This post is from Aug. 31, 2014, but I'm bumping it to the top of the queue as I am thinking about these matters in connection with Moretti and Sobchuk, Hidden in Plain Sight: Data Visualization in the Humanities (New Left Review 118, 2019, 86-119). They don't discuss this visualization, but they should have.In this post I suggest some studies I’d like to be done. I begin by recalling Moretti’s account of genre succession from Maps, Graphs, Trees in the context of Jockers’ massive graph of literary influence. Then I revisit the “Style” chapter and look at some of the work I passed over when I first posted on that chapter, the work related to Moretti’s generational observation. I then make some suggestions about how we could infer quasi-genres in the data assembled to build the influence graph and thereby extend Jockers’ work on style from his limited corpus of 106 texts to the larger corpus of 3346 texts. I conclude with some vague and tentative remarks about the pattern of reader interest betrayed in the record we’ve been examining, that of book publication.
Influence and Genre Succession
I’ve been thinking a lot about two things: 1) Moretti’s argument in Graphs, Maps, Trees that genres tend to cluster into 30 year cycles, and 2) Jockers’ massive graph in which all 3346 texts in his corpus are linked by relations of similarity, producing a graph that looks like this (which is Figure 9.3, p. 165; color version from the web):

As Jockers points out, what’s remarkable about this graph is that the nodes are ordered in time from left (oldest) to right, but there is no temporal information in the data from which it was derived: “Books are being pulled together (and pushed apart) based on the similarity of their computed stylistic and thematic distances from each other” (p. 164).
That temporal ordering is a side effect of ordering by thematic and stylistic similarity. But, in the abstract, it could have been otherwise, no? Why should positioning texts near similar texts result in temporal ordering? (Would the same thing be true of 20th Century texts?) This ordering implies that the evolution of literary culture IS directional, but Jockers himself hasn’t posited any telos, nor do I see any need to do so. That directionality stems from the internal dynamics of the system. Authors, and I assume audiences as well, want to stick with what they know, and what they know was published in the previous years.
It seemed to me that Moretti’s cycles must somehow be in that graph, for all the texts in a given cycle are close together in time, by definition, as well as similarity. Alas, the whole corpus has not been coded for genre (p. 158). Is there some way we can back into genre since we’ve got this massive graph based on similarity relations among texts along 578 dimensions? Aren’t texts within the same genre more likely to resemble one another than texts in different genres?
The other thing on my mind is the fact that what really interests me is what’s on people’s minds and how that evolves over time. Some books will attract few readers, some books many readers; but the mere fact that a book has been published doesn’t speak to that. Moreover, books can be read long after they’ve been published. In the case of Moby Dick, it would seem that, for the most part it was read only long after it was published. Publication history is, at best, an indirect proxy measure of that.
And yet that history IS a history. Assuming that publishers are for the most part rational economic actors who want to turn a profit, their decisions on what to publish must take into account their sense of what people are reading and therefore what they’re buying. And the kinds of books that got published changed from one decade to the next. That record of changes must reflect changes of reading taste.
Style and Genre, Again
Let’s start with Moretti. Here’s Figure 9 from Graphs, Maps, Trees (p. 19):
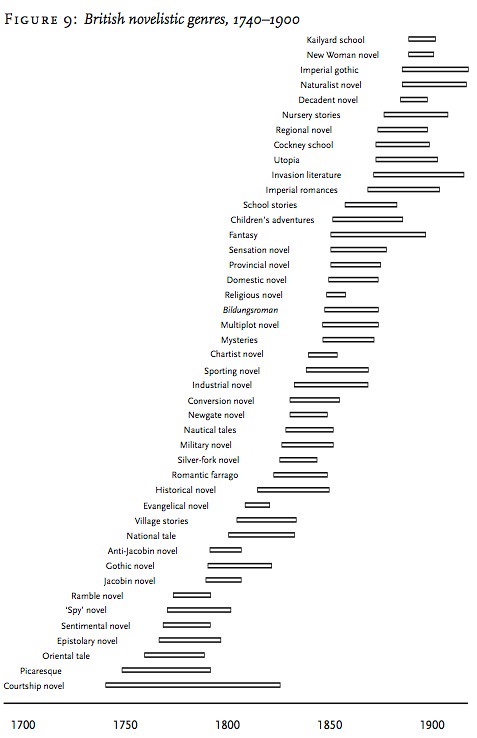
Here’s what Moretti says about it (p. 18-19):
Forty-four genres over 160 years; but instead of finding one new genre every four years or so, over two thirds of them cluster in just thirty years, divided in six major bursts of creativity: the late 1760s, early 1790s, late 1820s, 1850, early 1870s, and mid-late 1880s. And the genres also tend to disappear in clusters: with the exception of the turbulence of 1790–1810, a rather regular changing of the guard takes place, where half a dozen genres quickly leave the scene, as many move in, and then remain in place for twenty-five years or so. Instead of changing all the time and a little at a time, then, the system stands still for decades, and is then ‘punctuated’ by brief bursts of invention: forms change once, rapidly, across the board, and then repeat themselves for two– three decades: ‘normal literature’, we could call it, in analogy to Kuhn’s normal science.
Notice, however, that some genres seem to be longer-lived, courtship, picaresque, gothic, historical, industrial, and others.
Jockers looked into this phenomenon, though I’m only going to present the most superficial results in what is a fairly complex bit of analytic work. He used a corpus of 106 novels that Moretti classed into genres. Note that the corpus wasn’t selected to be representative of the whole sample (fn. p. 85). Here are the genres: historical, Newgate, Jacobin, Gothic, silver-fork, sensation, Bildungsroman, industrial, evangelical, national, and anti-Jacobin. Here is his Table 6.4, showing genres distributed by decade (p. 85):

Table 6.4: distribution of novel genres over time
Notice first of all that the numerical values are percentages, not absolute number of texts, and that it is the row values that add up to 100%. Thus, for example, 100% of the Jacobin novels were published in the 1790s and 40% of the anti-Jacobin novels were published in the 1790s and 60% in the 1800s, and so forth. That table Jockers notes, looks rather like Moretti’s Figure 9, except that it has percentages added. What’s interesting is that novels in each genre are not spread evenly across decades–which in any event, as Jockers notes, are somewhat arbitrary time periods.
Jockers then presents another table, Table 6.5 (p. 87) designed so that the percentages in each column add up to 100%:

Table 6.5: Genre composition by decade
What we see is that genres are not equally represented in each decade. Notice, for example, that the national (Natl) novel is distributed 38% and 63% over the decades 1800 and 1810 (Table 6.4) respectively. While it constitutes 33% of the texts in the 1800s, its relative contribution to the 1810s is smaller (Table 6.5), despite the face that that’s when a greater portion of its output appeared.
What would comparable tables look like for all genres and all texts? As the full 3346-item corpus hasn’t been scored for genre we don’t know. But maybe it would be possible to get something as useful without having to score all the texts.
Tracing genre/similarity through time
As we’ve seen, Jockers HAS calculated similarity between texts for the entire corpus where each text is scored on 578 different features. With one proviso, one would think that two texts of the same genre would be more like one another than two texts from different genres. Jockers’ work on style suggests that texts by the same author in different genres may score as being more alike one another than two texts from the same genre, but by different authors. As we shall see, given the way that Jockers calculated similarity, that can be controlled for.
Here’s what I’d like to do. First let’s classify the entire corpus into 40-50 classes (recall that Moretti had 44 genres) using some appropriate procedure. We can call these quasi-genres if you wish, as we don’t know how well they’ll line up with Moretti’s (or anyone else’s) genre classifications. With that done, we: 1) divide the corpus into bins by decade and then, 2) track the evolution of each quasi-genre from one decade to another.
What I’m looking for, of course, is a result resembles that pattern exhibited jointly in Jockers’ Tables 6.4 and 6.5. For any given quasi-genre there will be decades where it doesn’t appear at all; there will also be decades where it makes a relatively small contribution to the decade and others where it makes a large contribution. How many of these quasi-genres exhibit a 30-year life cycle that begins small in one decade, peaks in the text, and tapers off in the third?
Now, how do we allow for the fact that authorial identity may confound similarity judgments by linking texts by the same author but in different genres? As you’ll recall, there are two classes of features in 578-item feature set that Jockers is using. While the numerical breakdown is not clear to me from what Jockers says, roughly 150-160 features would be function words and punctuation marks and the rest would be content words (all of them nouns). Jockers used the content word features for thematic analysis (Chapter 8; posts 6.1, 6.2, 6.3, and 6.4 in this series) and other, smaller, feature set for style (Chapter 6; posts 3.0 and 3.1 in this series). The potentially confounding author signals are in the stylistic feature set. We simply don’t know whether there is also an author signal in the thematic feature set.
I propose that the above analysis be done three times: 1) on the full 578 feature set, 2) using only the theme feature set, to eliminate the known author signals, and 3) using only the style feature set. How do the results compare?
A meshwork of transactions
Finally, what, if anything, can we do about the fact that we aren’t looking directly at a picture of what interested readers at various times? We’re only looking at what books were published. Unless those publishers were more astute than contemporary publishers, many of those books would not have earned back their publication costs much less have made a profit.
I don’t have anything very specific to offer here. But I can’t help but think that there’s something to be found. So I’ll make some loose observations.
First, among those 3346 texts are few have become canonical. Those texts found audiences and there now exist an institutional infrastructure of schools and libraries that keeps those texts in circulation. Some of those texts were popular in their time (e.g. those of Austen, Dickens, or Twain) and some were not (e.g. Moby Dick). What kinds of relationships do these texts have with that whole corpus?
That generation-long period, 30 years, itself interests me. After all, it’s not as though we’re dealing with ideal readers that never die. But let us imagine that that is what we in fact had. That is, imagine that these texts were being read by and sold to a closed set of timeless readers who were alive at the beginning of the period and who are still alive at the end. No new timeless readers are born during that period.
If that were the case, then we’d have no choice but to argue that genre succession reflects changes in the interests of these timeless readers. Once they’ve read a book there’s no point in reading it again and when they’ve read enough books of a given kind, the whole genre becomes stale and it’s time to look for something else. But that’s not what we have.
We have a changing population. People are born, mature, and die and their interests change over the course of their life. A genre that was new and shiny for one cohort is seen by a later cohort as the old books of their parents or grandparents. Yet, people are born and die more or less continuously, not in the spurts that Moretti sees. Where do those spurts come from?
Why spurts at all? That’s the question. Why does change happen in spurts rather than continuously?
Here’s what I’m thinking. Stories are vehicles through which people form communities of values. As people grow up ann enter the community, they adopt the stories of that community. But the world is changing–as it was in Europe and North America during the 19th Century–and a given body of stories becomes less and less suitable for the community function, but still, people make things fit. The genre “stretches and strains” and people adapt themselves to the stories at hand, though perhaps with some discomfort.
The history of astronomy has a crude but useful analogy. The geocentric model of the universe put the earth at the center. In order to incorporate new observations about planetary movement into the model, astronomers had to keep adding epicycles to the model. Thus over time the model became more and more complex as more epicycles were added. At some point Copernicus said “Enough!” and created a new model, one centered on the sun. The number of epicycles dropped dramatically, though it didn’t altogether disappear.
So, I say, it went with novels. At some point the youngest members of the community discover some texts of a new kind that they find more congenial. Wham! So they defect from the old community and gather around a new set of genres. And the process continues. At first these new genres are well suited to the rising community of readers. But it time, it will be less and less suitable.
This, of course, implies that there’s some standard of fitness against which texts are being measured. What is it? Whatever it is, though, it’s an aesthetic standard.
That’s merely a just-so story, one that suffers moreover because it is a vague just-so story. It’s the best I can do at the moment. But I think that something like that is lurking in the pattern of genre succession.
* * * * *
Previously:
- Reading Macroanalysis 1: Framing: Hyperobjects, Objectification, and Evolution
- Reading Macroanalysis 2: Metadata and the Emperor’s New Clothes
- Reading Macroanalysis 2.1: How do we make inferences from patterns in collections of books to patterns in populations of readers?
- Reading Macroanalysis 3.0: Style, or the Author Comes Back from the Dead
- Reading Macroanalysis 3.1: Style, or Measuring the Autonomous Aesthetic Realm
- Reading Macroanalysis 4: On the matter of “the”
- Reading Macroanalysis 5: An Interlude on Scale: Micro, Meso, and Macro
- Reading Macroanalysis 6.1: Theme–Dogs, Gold, Slavery, and Awakening
- Reading Macroanalysis 6.2: Theme, Moby Dick in the Context of Literary Culture
- Reading Macroanalysis 6.3: DOGS and BIRDS, or, the hermeneutics of screwing around
- Reading Macroanalysis 6.4: Themes and how they evolve over time
- Reading Macroanalysis 7: Influence, or the evolving dynamic integrity of the aesthetic sphere
- Reading Macroanalysis 7.1: Visualizing the Geist of 19th Century Anglo-American Literary Culture
- Reading Macroanalysis 7.2: Hyperobjects and Large Finitude
I have collected all these posts, plus one more final post, into a single working paper: Reading Macroanalysis: Notes on the Evolution of Nineteenth Century Anglo-American Literary Culture (2014).
No comments:
Post a Comment