If, a few years ago, you’d asked me whether or not a half dozen scholars could have an interesting and fruitful conversation 280 characters at a time, I’d have said “Are you freakin’ kidding me?”–or words to that effect. But it happens, not all the time, but often enough, and it even happened when we were restricted to 140 characters at a time. Such is life in the academic Twittersphere.
Ted Underwood kicked one off on Friday (the 13th, FWIW) and it continued on into Saturday. A half dozen or so joined in and who knows how many followed along–a dozen, 30, 50, more, who knows? I don’t know what Ted expected when he threw that first tweet into the maelstrom, nor does that much matter. What matters is what happened, and that was unplanned, spontaneous, even fun.
Of course, it requires interlocutors who understand the issues at hand well enough that they can speak in code. And they need to read one another charitably and in good faith. But, given those conditions, it is possible to do some good work.
But enough of this. Let’s get to it.
In the next section of this post I reproduce three tweets from that conversation and add some commentary. These set the stage for the next two sections, where I use the well-known Stanford Literary Lab Pamphlet 4 to interrogate the issues raised in the first section; this fleshes out an argument I tossed into the conversation in a five-tweet string.
Dropping science in the Twitterverse
Here’s the tweet that started things off:
As we look at new quantitative evidence about literary history, and try to sort it into "things we knew / or didn't," we should also list things we *thought* we knew that we're not finding much evidence for. Dogs that might have been expected to bark. E.g., period boundaries.— Ted Underwood (@Ted_Underwood) July 13, 2018
So, yeah, it’s a bit aggressive: maybe the received wisdom ain’t necessarily so (as the song goes). And periodization is just dropped in there at the end, as a for-example. Of course, it’s an important case because literary studies is more or less organized according to periods: fields of study, journals, conferences, professional organizations, coursework, all organized by period. To be, period isn’t the only parameter of organization, we’ve also got author, genre, and a blither or theoretical proclivities, but it’s an important one.
And it’s one that Underwood has investigated. Here’s the abstract of an article he and Jordan Sellers recently published, The Longue Durée of Literary Prestige [1]:
A history of literary prestige needs to study both works that achieved distinction and the mass of volumes from which they were distinguished. To understand how those patterns of preference changed across a century, we gathered two samples of English-language poetry from the period 1820–1919: one drawn from volumes reviewed in prominent periodicals and one selected at random from a large digital library (in which the majority of authors are relatively obscure). The stylistic differences associated with literary prominence turn out to be quite stable: a statistical model trained to distinguish reviewed from random volumes in any quarter of this century can make predictions almost as accurate about the rest of the period. The “poetic revolutions” described by many histories are not visible in this model; instead, there is a steady tendency for new volumes of poetry to change by slightly exaggerating certain features that defined prestige in the recent past.
Those “poetic revolution” imply period boundaries, but those boundaries didn’t show up. To be sure, the model did show change, but it was gradual and seemed to have a historical direction–which is a whole different kettle of conceptual and perhaps even ideological fish.
I rather liked that work, and took a close look at it [2]. I particularly liked the apparent directionality it revealed, but let’s set that aside. As for the lack of period boundaries...well, I don’t think periodization is simply a matter of disciplinary hallucination. So I’m inclined to think that the method Underwood and Sellers used simply isn’t sensitive to such matters. But that’s not an argument; it’s merely a casual assertion. Underwood is right, there IS work to be done.
And that’s what caught people’s attention. Daniel Shore entered and exchanged tweets with Ted. Then I suggest color perception as an analogy:
Hmm... Does the lack of a clear boundary between the Romantic novel & the Victorian novel imply that there is no significant difference? Color may slide continuously from blue to green, but that doesn't mean that the color of grass is indistinguishable from the color of they sky.— Bill Benzon (@bbenzon) July 13, 2018
In making that suggestion I had more in mind than the mere presence of categories over continuity. Color perception is tricky, and much studied. We know, and have know so for quite awhile, that there isn’t a simple and direct relationship between perceived color and wavelength of light. This is not the place for a primer in color vision (the Wikipedia article is a reasonable place to begin). But I can offer a few remarks.
Blue, for example, does not map directly to a fixed region in the electromagnetic spectrum, with violet and green in adjacent fixed regions. The color of a given region in the visual field is calculated over input from three kinds of retinal receptors (cones) having different sensitivities. Moreover the color of one region is “normalized” over adjacent regions. The upshot is that a red apple will appear to be red under a wide range of viewing conditions. Different illumination means different wavelengths incident on the apple. Hence light that the apple reflects to the eye varies in different situation. Because the brain normalizes, the apple’s color remains constant.
We’ll return to part of that story a bit later.
Let’s return to the twitter conversation with a pair of remarks by Ryan Heuser:
e.g. How can we maintain the contradiction between continuous historical change and historical periods, without trying to resolve it by rejecting the latter for the former? Seems to me that finding a way in which both are true would be the more significant form of new knowledge.— Ryan Heuser (@quadrismegistus) July 13, 2018
The conversation continued on. Others joined. It forked here and there. And somewhere in there I introduced a string of tweets about Lit Lab 4.
19th Century British Novels
Lit Lab 4: Heuser and Le-Khac, A Quantitative Literary History of 2,958 Nineteenth-Century British Novels: The Semantic Cohort Method (Literary Lab, Pamphlet 4, May 2012). Why bring it up? In the first place, examples are good. Second, it’s a well-known piece of work that’s received considerable discussion. It covers a century’s worth of texts, but was not organized around the idea of periods and did not discuss them. And, of course, Heuser was a participant in the current discussion.
I started skimming through the text, looking for a graph that would speak to the issue of discontinuity arising from continuity. And I found one, Figure 18: Spectrum of novels, authors, and genres as ranked by concentration of the abstract values fields. Let’s work up to it.
As you may recall, they ended up tracking the prevalence of two cohorts of words through their corpus: Abstract values (social restraint and moderation, moral evaluation, sentiment, objectivity), and so-called “hard-seed” words (because they turned up when they fed “hard” into their correlator). The hard-seed words included action verbs, body parts, colors, numbers, locatives, and physical adjectives. Their Figure 8 (p. 18) tracks the prevalence of the abstract value words:
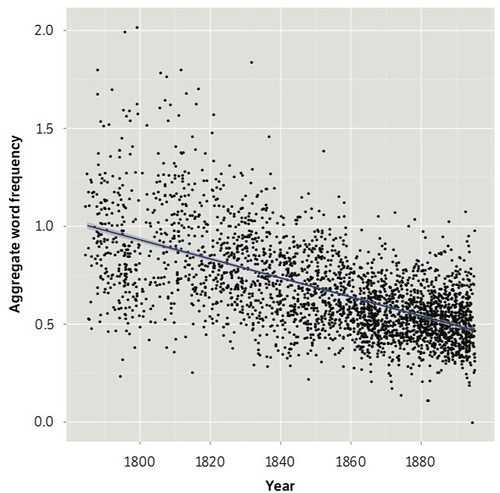
And their Figure 15 (p. 27) tracks the hard seed words:
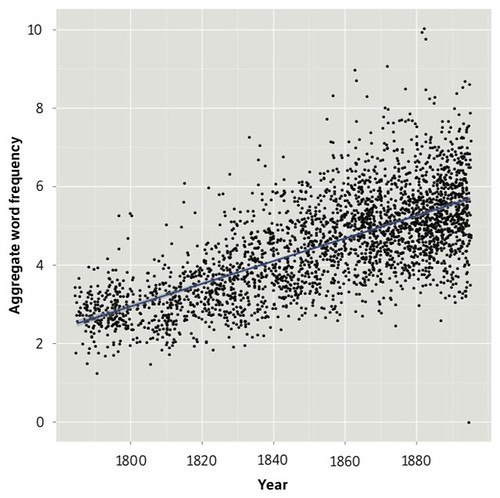
Both cohorts “move” continuously through the century, but one waxes while they other wanes, which we see in Figure 17: Inverse relationship of abstract values and hard seed word frequencies in novels (p. 31):
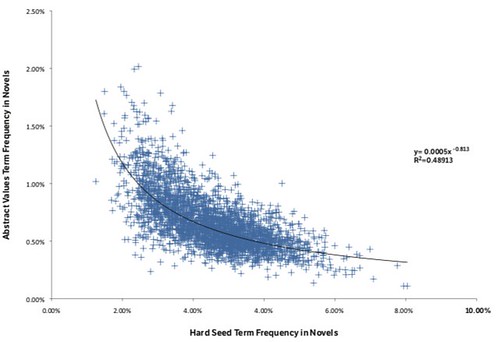
This brings us to Figure 18 (p. 32):
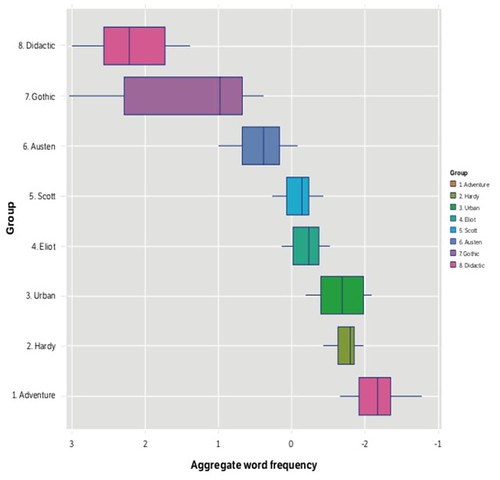
Here’s their caption:
Spectrum of novels, authors, and genres as ranked by concentration of the abstract values fields. The x- axis shows number of standard deviations above the corpus-wide mean concentration of abstract values fields. For example, the median for the evangelical and didactic novels was around 2.25 standard deviations above the mean.
And here’s some commentary (pp. 32-33):
Ranking novels by their usage of the two fields indeed separates out clusters of genres and authors within the spectrum (see Figure 18). From left to right, this shows novels with highest frequency of abstract values words to lowest (and, conversely, lowest frequency of “hard seed” words to highest). What we get is a distribution that begins at the extreme lft with the evangelical novel, closely followed by the Gothic novel, then Jane Austen, Walter Scott and George Eliot. Toward the right of the spectrum, we find the urban and industrial novel and Charles Dickens, and at the extreme right, a cluster of genres including adventure novels, fantasy, science fiction, and children’s literature. Given that it was generated quantitatively by the concentration of only two features of novelistic language, and that obviously computers have no knowledge of authors or genres, it’s amazing just how suggestive the spectrum is. For instance it clusters city novels together and takes Eliot’s works out of chronological order and places them back a generation closer to Austen’s, bringing out an affinity that many readers and critics have felt. Because of this sensitivity to genres and authors, the spectrum allowed us to see the two historical trends in novelistic language as deeper shifts in narrative mode, changes in the kinds of novels being written.
What can we make of this?
First, it doesn’t speak directly to Underwood’s particular example. Yes, in both cases we’re looking at the 19th century, but Underwood and Sellers looked at poems while Heuser and Le-Khac looked at novels. Moreover their methods were quite different. Underwood and Sellers trained a machine learning model of literary prominence while Heuser and Le-Khac analyzed word frequencies.
Second, pace Heuser, there doesn’t seem to be any conflict between DH and “H” in this particular case. “H” distinguished between Victorian and Romantic novels and DH managed to locate that boundary in the process of examining data exhibiting continuous change through the century.
Now, let’s think about the color analogy. As I indicated, the visual system calculates color as a function of the outputs from three types of receptor, each with a different spectral sensitivity. Heuser and Le-Khac have, in effect, “calculated” genre and literary period as a function of input from two types of semantic “receptors”.
At the end of the pamphlet they offer some methodological reflections (p. 48):
In moving from signal to concept, from numbers to meaning, what may be needed in fact is more numbers. More numbers and different kinds of numbers. As humanists, we may fear that gathering more quantitative data only moves us farther from the qualitative meaning we seek, but we’re suggesting that having more kinds of data actually moves us closer to finding meaning.
And (p. 49):
This approach can be summarized as a hypothesis-testing mode of interpretation. Engaged in a constant dialogue between evidence and interpretation, hypothesis testing seeks to eliminate potential theories by testing them against multiple forms of data, resulting in a stronger argument. The focus shifts from whittling away data that do not fit our theories to whittling away theories that do not fit the data.
How ingenious, how–dare I say it?–natural.
Addendum
I just got a note from Franco Moretti: “I have always been a fan of that figure with the 7 genre groups.” My response: “Now if we can get ten such figures, from a half dozen or so different research groups, with 10 different collections of texts, then we’ve got something.”
Addendum
I just got a note from Franco Moretti: “I have always been a fan of that figure with the 7 genre groups.” My response: “Now if we can get ten such figures, from a half dozen or so different research groups, with 10 different collections of texts, then we’ve got something.”
References
[1] Ted Underwood and Jordan Sellers, The Longue Durée of Literary Prestige, Modern Language Quarterly 77:3 (September 2016)
DOI 10.1215/00267929-3570634
[2] William Benzon, On the Direction of 19th Century Poetic Style, Underwood and Sellers 2015, Working Paper, June 2015, 31 pp. https://www.academia.edu/13279876/On_the_Direction_of_19th_Century_Poetic_Style_Underwood_and_Sellers_2015
Note that I based these remarks on a preprint version of the paper, not the published one.
No comments:
Post a Comment