1. Entropy doesn’t measure disorder, it measures likelihood.
Really the idea that entropy measures disorder is totally not helpful. Suppose I make a dough and I break an egg and dump it on the flour. I add sugar and butter and mix it until the dough is smooth. Which state is more orderly, the broken egg on flour with butter over it, or the final dough?
I’d go for the dough. But that’s the state with higher entropy. And if you opted for the egg on flour, how about oil and water? Is the entropy higher when they’re separated, or when you shake them vigorously so that they’re mixed? In this case the better sorted case has the higher entropy.
Entropy is defined as the number of “microstates” that give the same “macrostate”. Microstates contain all details about a system’s individual constituents. The macrostate on the other hand is characterized only by general information, like “separated in two layers” or “smooth on average”. There are a lot of states for the dough ingredients that will turn to dough when mixed, but very few states that will separate into eggs and flour when mixed. Hence, the dough has the higher entropy. Similar story for oil and water: Easy to unmix, hard to mix, hence the unmixed state has the higher entropy.
Tuesday, July 31, 2018
Sabine Hossenfelder clarifies entropy

The subjective nature of meaning
Note: You may consider this to be deep background for my ongoing examination of Michael Gavin’s recent article on Empson, vector semantics, and Milton [1]. But it may also be understood independently of that discussion
It seems to me that the meaning of literary texts, as studied by literary critics, is ineluctably and irreducibly subjective. But we must be careful about that word “subjective”, for it has come to imply (often wild) variation from one person to another. While meaning may well vary from one person to another – the meanings literary critics discover through so-called close reading certainly vary among critics – that is not what interests me here. By subjective I mean simply that it is a phenomenon that exists in the mind of, you know, subjects. Whether or not meaning varies between subjects is a different matter. Color is subjective in this sense, though it is pretty constant across different people, color blindness providing the major exceptions.
(You might want to consult John Searle on subjectivity and objectivity in the ontological and epistemological senses. I am here asserting that meaning is ontologically subjective and leaving its epistemological status out of the conversation.)
Walter Freeman's neuroscience of meaning
The later Walter Freeman was interested in such things. I want to look at two paragraphs from a collection of his papers: Walter J. Freeman. Mesoscopic Brain Dynamics. London: Springer-Verlag Limited, 2000.
These paragraphs are from the Prolog, which introduces the papers. One paragraph is fairly technical in its content while the following one is more accessible and can, in fact, be understood without having read the first one. So, I’m going to start with that second paragraph and then give you the first one. Moreover, I’m going to give you the first one twice. I insert some interpretive remarks into the repetition.
Here then is what Freeman has to say about meaning in the brain (pp. 9-10):
The point here is that brains do not process “information” in the commonly used sense of the word. They process meaning. When we scan a photograph or an abstract, we take in its import, not its number of pixels or bits. The regularities that we should seek and find in patterns of central neural activity have no immediate or direct relations to the patterns of sensory stimuli that induce the cortical activity but instead to the perceptions and goals of human and animal subjects. Far from being fed into our cortices in the way that we program and fill our computers, everything that we know and can remember has been constructed by the global self-organizing dynamics of activity within our brains.
That paragraph interprets this more technical and more specific one (p. 9):
... the bulbar AM patterns do not relate to the stimulus directly but instead to the meaning of the stimulus, as shown in several ways. The simplest way is to switch a reward between two odorants, so that the previously rewarded stimulus is no longer reinforced and vice versa. Both AM patterns change, though the two odorants do not. So also does the spatial pattern for the control segments in back- ground air. So also do all pre-existing AM patterns change when a new odorant is added to the repertoire. The AM patterns for all odorants that can be discriminated by a subject change whenever there is a change in the odorant environment. Furthermore, when rabbits are trained serially to odorants A, B, C, D, and then back to A, the original pattern does not recur, but a new one appears (Freeman and Schneider 1982; Freeman 1991a). This property is to be expected in a true associative memory, in which every new entry is related to all previous entries by learning, because the context and significance are subject to continual and unpredictable change.
Now I insert some interpretive remarks in italics:
... the bulbar AM patterns do not relate to the stimulus directly but instead to the meaning of the stimulus, as shown in several ways.“Bulbar” refers to the olfactory bulb, a cortical structure involved with smell. “AM” is amplitude modulation. Freeman is recording electrical patterns from an array of electrodes touching the surface of the olfactory bulbs of “small laboratory animals”, Freeman’s phrase, generally rats or rabbits. Think of the AM patterns as signals.The simplest way is to switch a reward between two odorants, so that the previously rewarded stimulus is no longer reinforced and vice versa. Both AM patterns change, though the two odorants do not. So also does the spatial pattern for the control segments in background air.Note that the olfactory bulb is “upstream” from the olfactory receptors in the nasal cavity. Those receptors “relate to the stimulus directly”, while the bulbar AM patterns are suffused with meaning.So also do all pre-existing AM patterns change when a new odorant is added to the repertoire. The AM patterns for all odorants that can be discriminated by a subject change whenever there is a change in the odorant environment.That is to say, when a new odorant is learned a new pattern must be added to the existing array of patterns. But it is not merely ADDED TO array, leaving the existing one unchanged. All the preexisting patterns change.Furthermore, when rabbits are trained serially to odorants A, B, C, D, and then back to A, the original pattern does not recur, but a new one appears (Freeman and Schneider 1982; Freeman 1991a). This property is to be expected in a true associative memory, in which every new entry is related to all previous entries by learning, because the context and significance are subject to continual and unpredictable change.Digital computers do not use associative memory. Items in computer memory are accessed through their addresses. In associative memory there are no addresses independent of items in memory. Associative memory is said to be content addressed.
Note that Freeman thus has an objectively way of examining of phenomenon that is fundamentally subjective. But then students of color perception have been doing that for years.
Are all psychological phenomena thus (ontologically) subjective? How could they not be?


Monday, July 30, 2018
Gavin 1.2: From Warren Weaver 1949 to computational semantics [#DH]
In the first post in this series (Gavin 1.1: Warren Weaver (1949) and statistical semantics) I suggested that what Gavin [1] calls “computational semantics” might more accurately be called “statistical semantics” and went on to offer some remarks about statistical semantics using Warren Weaver’s 1949 memorandum, “Translation” [2], as my starting point. The purpose of this post is to offer some remarks about a different body of work in semantics, again making reference to Weaver’s 1949 memorandum.
As far as I know there is no standard term for this other body of work that would differentiate it from statistical semantics while still indicating that it is computational in nature. I have no interest in policing anyone’s usage of language and realize that terms have life of their own. Still, as a practical matter, I need to make a distinction and so, for the purposes of this post, I will use the term “computational semantics” for this other body of work.
This post will not be quite so straightforward as that first one. First I want to say a bit about how the collapse of funding for machine translation (MT) was followed by work on the problem of language understanding. That’s a story that Gavin didn’t tell, presumably because it isn’t relevant to the substance of his essay. But I’d have been a bit happier if he’d at least mentioned that the research had been undertaken.
In the next section I return to Weaver’s memo, where he mentions having talked with one Dr. Richens. That will bring us back to Gavin’s story by way of Cambridge Language Research Unit (CLRU) founded by Margaret Masterman. From there I move to work I had participated in during my graduate study, the use of computational semantics in the study of abstract concepts and of topic analysis. I will give the last word to Martin Kay, one of the grand old men of computational linguistics.
The over all effect of this post is to take Gavin’s article as a framework within which I tell a story he glossed over. In the next post I will take a look at his discussion of a passage from Milton using statistical semantics and juxtapose it against work I did on Shakespeare’s Sonnet 129 using computational semantics.
From MT to language understanding
As Gavin has indicated, research into MT was catalyzed by Weaver’s memorandum and funded largely by the Defense Department (pp. 649-650). By the early 1960s achievements lagged far behind expectations and the federal funding dried up. As Victor Yngve noted (quoted in Brian Lennon [3] p. 143):
[w]e have come face to face with the realization that we will only have adequate mechanical translations when the machine can “understand” what it is translating and this will be a very difficult task indeed.
And that, understanding, is what many researchers decided to tackle, though under the broader rubric of computational linguistics. They were joined by researchers in AI and cognitive science.
Gavin leaves MT at this point and turns to the emergence of statistical semantics and to Margaret Masterman, whom I’ll mention in the next section. But I want first to take a brief look at computational semantics. The body of relevant work is vast and I have no intention of attempting to indicate the whole [4]. But I want to look at one seminal system.
In the late 1960s Terry Winograd constructed the SHRDLU system while a graduate student at MIT [5]. Like most AI systems it was designed to work in a very restricted world, in this case, a world of blocks. The user interacts with the system using natural language, typing commands and making queries, and viewing the state of the blocks world on a graphics terminal. Here is a fragment of typical dialog:
Person: Pick up a big red block.Computer: OK.Person: Grasp the pyramid.Computer: I DON'T UNDERSTAND WHICH PYRAMID YOU MEAN.Person (changing their mind): Find a block which is taller than the one you are holding and put it into the box.Computer: BY "IT", I ASSUME YOU MEAN THE BLOCK WHICH IS TALLER THAN THE ONE I AM HOLDING.Computer: OK.Person: What does the box contain?Computer: THE BLUE PYRAMID AND THE BLUE BLOCK.Person: What is the pyramid supported by?Computer: THE BOX.Person: How many blocks are not in the box?Computer: FOUR OF THEM.Person: Is at least one of them narrower than the one which i told you to pick up?Computer: YES, THE RED CUBE.Person: Is it supported?Computer: YES, BY THE TABLE.Person: Can the table pick up blocks?Computer: NO.Person: Can a pyramid be supported by a block?Computer: YES.Person: Can a pyramid support a pyramid?Computer: I DON'T KNOW.Person: Stack up two pyramids.Computer: I CAN'T.Person: Will you please stack up both of the red blocks and either a green cube or a pyramid?Computer: OK.
Primitive? Yes. But at the time it was a remarkable achievement. The point is simply that the user could interact with the machine using natural language, rather than a computer language, and the computer would respond appropriately. The machine understands language in the sense that it responds appropriately to natural language discourse, albeit of a very limited range. That was new.


Socialism and democracy
Corey robin, "Why the argument for democracy may finally be working for socialists rather than against them", Crooked Timber, July 27, 2018.
Throughout most of my life and before, if you raised the banner of socialism in this country or elsewhere, you had to confront the question of Stalinism, Soviet-style sham elections, one-party rule, and serial violations of any notion of democratic proceduralism. No matter how earnest or fervent your avowals of democratic socialism, the word “democracy” put you on the defensive.What strikes me about the current moment is how willing and able the new generation of democratic socialists are to go on the offensive about democracy, not to shy away from it but to confront it head on. And again, not simply by redefining democracy to mean “economic democracy,” though that is definitely a major—the major—part of the democratic socialist argument which cannot be abandoned, but also by taking the liberal definition of democracy on its own terms.The reason this generation of democratic socialists are willing and able to do that is not simply that, for some of them, the Soviet Union was gone before they were born. Nor is it simply that this generation of democratic socialists are themselves absolutely fastidious in their commitment to democratic proceduralism: I mean, seriously, these people debate and vote on everything! It’s also because of the massive collapse of democratic, well, norms, here at home.
Comparative politics:
If you took a comparative politics class in college during the Cold War, it would have discussed the nature of the Communist system, which was distinguished from a democratic system by the merger of the Party and the state, becoming a party-state. Well, the United States is also a party-state, except instead of being a single-party state, it’s a two-party state. That is just as much of a departure from the norm in the world as a one-party state.In the United States, the law basically requires the Democrats and the Republicans to set up their internal structures the way that the government instructs them to. The government lays out the requirements of how they select their leaders and runs their internal nominee elections, and a host of other considerations. All this stuff is organized by state governments according to their own rules. And of course when we say state governments, who we’re talking about the Democrats and the Republicans.So it’s a kind of a cartel arrangement in which the two parties have set up a situation that is intended to prevent the emergence of the kind of institution that in the rest of the world is considered a political party: a membership-run organization that has a presence outside of the political system, outside of the government, and can force its way into the government on the basis of some program that those citizens and members assemble around.
Some lists of influential books
The 20 Most Influential Academic Books of All Time: No Spoilers https://t.co/3SsXsvCQob pic.twitter.com/KHEZzQp8cc— Open Culture (@openculture) July 30, 2018
The link takes you to an article that not only lists the top 20 academic books as determined by "expert academic booksellers, librarians and publishers" but contains other interesting lists as well. I would also observe that the academic top 20 is a mixed bag.
Sunday, July 29, 2018
The few and the many, Europe and the USofA
This is … quite a chart. https://t.co/xkX2WCbLSI pic.twitter.com/2rc4zxoNKm— Alan Jacobs (@ayjay) July 29, 2018
Virtual Reading as a path through a high-dimensional semantic space [#DH]
Over the past year of so I’ve been thinking about computing virtual readings of texts where the reading is in effect a path through a high-dimensional sematic space. I’ve even written a working paper about it, Virtual Reading: The Prospero Project Redux. I’ve just now discovered that Andrew Piper has taken steps in that direction, though not in those terms. The paper is:
Andrew Piper, Novel Devotions: Conversional Reading, Computational Modeling, and the Modern Novel, New Literary History, Volume 46, Number 1, Winter 2015, pp. 63-98. DOI: https://doi.org/10.1353/nlh.2015.0008
Piper is interested in conversion stories in autobiographies and novels. He’s also interested in making a methodological point about an exploratory style of investigation that moves back and forth between qualitative and quantitative forms of reasoning. That’s an interesting and important point, very important, but let’s set it aside. I’m interested in those conversion stories.
He takes Augustine’s Confessions as his starting point. Augustine puts the story of his conversion near the end of Book 8, of thirteen. Do the chapters prior to the conversion take place in a different region of semantic space from those after the conversion? With chapters (Augustine calls them books) as analytic unit, Piper uses multidimensional scaling (MDS) to find out. I’ve taken his Figure 2 and added the shading (p. 71):
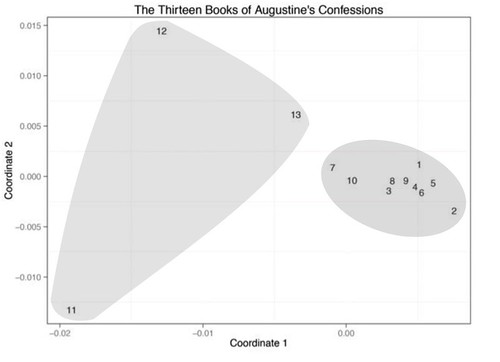
We can see that books 1-10 occupy a position in semantic space that’s distinctly different from books 11-13 and, further more, that “The later books are not just further away from the earlier books, they are further away from each other” (p. 72). Now, though Piper himself doesn’t quite do so, it is easy enough to imagine each book as a point in a path, and track that path through the space.
But Piper does note that “Book 13 appears to return back to the original ten books in more circular fashion” (p. 71) and that, by a standard statistical measure, Book 13 belongs with 1-10. In the following figure I’ve highlighted both the relationship between Books 1 and 13 and the long leap between 10 and 11:
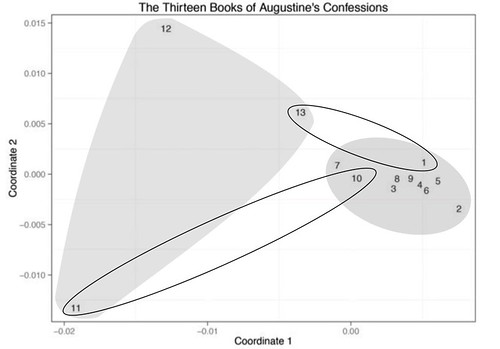
From there Piper goes on to develop a pair of numerical measures that allows him to test a body of texts (450 of them) for this kind of semantic structure. Which is all well and good.
But I want to dwell on the mere fact that Piper has, in effect, shown that Augustine’s course through the Confessions moves through distinct regions of semantic space and that we have statistical tools we can use to trace such paths. Now, Piper used the chapter as his unit of analysis. That’s a rather large unit, yielding a rather crude approximation of the reader’s path. Hey, Jake. How do you drive from New York to LA? Well, I generally go to Pittsburgh, then St. Louis, Denver and then LA. Well, yeah, sure. That’s the general idea. But as driving instructions, it’s not very useful.
What if Piper had used 1000-word chunks, or paragraphs, perhaps even sentences, as a unit of analysis? I surely don’t know. It’s quite possible that, for his purposes, the added detail would have little or no value. But it might be that a more find-grained analysis would show that there are places in 1-10 territory where the path stray over there into 11-13 territory. And if so, what then? Who knows? We won’t know until we take a look.
I note finally that this is a kind of formal analysis. When Piper looks for similar texts, he's look for geometrical congruence that is independent of the specific semantic values of the underlying space.
For more thoughts in this, check out my working paper, Virtual Reading: The Prospero Project Redux, where I discuss Heart of Darkness and Shakespeare.
I note finally that this is a kind of formal analysis. When Piper looks for similar texts, he's look for geometrical congruence that is independent of the specific semantic values of the underlying space.
For more thoughts in this, check out my working paper, Virtual Reading: The Prospero Project Redux, where I discuss Heart of Darkness and Shakespeare.

Ergoticity
For maximum benefit fun be sure to watch the animation:
However....
A billiard ball in a rectangle with two circular ends: slight changes in initial conditions make such a big difference that eventually it could be anywhere. To be precise, we say its motion is "ergodic".— John Carlos Baez (@johncarlosbaez) July 28, 2018
This animation was made by @roice713.
(to be continued) pic.twitter.com/rQPS0OOdXH
For the precise definition of "ergodic" read my diary:https://t.co/kcgMZNahqv— John Carlos Baez (@johncarlosbaez) July 28, 2018
A billiard ball moving in a convex region with smooth boundary can't be ergodic. In fact, in 1973 Lazutkin showed this for a convex table whose boundary has 553 continuous derivatives!
However....
I appreciate the tag and am glad I get to follow this thread now, but also need to correct the attribution - the animation was by Phillipe Roux :) https://t.co/8HVbdDZ2dW— Roice (@roice713) July 28, 2018
* * * * *
No particular region of the space is priviliged. No matter where the billiard ball starts, in time it could be anywhere. A bit more exactly (Wikipedia):
In probability theory, an ergodic dynamical system is one that, broadly speaking, has the same behavior averaged over time as averaged over the space of all the system's states in its phase space. In physics the term implies that a system satisfies the ergodic hypothesis of thermodynamics.
Saturday, July 28, 2018
Another ramble to figure out what I’m up to: space travel, peace, Joe Rogan, computational lit crit [Ramble 11]
It’s time for a bit of rambling so I can take stock and figure out where I am & where I need to go.
GVMBP 2018

Sunday I posted some photos from Saturday’s Massive Block Party, thrown by Green Villain, Writer’s Workbench, and VYV Apartments. More on went up on Tuesday.
Onward Ho!
On Sunday I uploaded another essay to 3 Quarks Daily: Three Children Of The Space Age: Elon Musk, Freeman Dyson, And Me. That essay, of course, goes deep into my past, up through the present and, who knows, maybe into the future. But I wrote it as kind of an outer out-there bounds to a project I’ve been working on with Charlie Keil, a series of little books, or pamphlets, on the theme: Local Paths to Peace Today. We published the first volume two years ago: We Need a Department of Peace: Everybody's Business, Nobody's Job.
 |
| Ralph Nader with his copy of We Need a Department of Peace |
We’ve just sent the second volume off to press: Thomas Naylor’s Paths to Peace: Small is Necessary. That’s about how everything’s too damn big, especially the states we live in. We’re now working on a third volume which doesn’t have a title yet (though CK likely has something he’s thinking about). For the moment let’s call it Where We Want to Go: Cooperation and the Common Glad Impulse.
Well, I figure we need to present some scenario for a different future, the opposite of those dystopian scenarios I wrote for Abbe Mowshowitz two decades ago. Now, you see, CK is something of a Luddite and has no interest in manned space travel, but I’m a bit different. Elon Musk has interesting things to say about where we’re going and how we get there, so I figured that would be a good warm-up.
Moving closer to Where We Want to Go, I’m participating in a group reading of Kim Stanley Robinson’s New York 2140, which is about a future in which the seas have risen 50 feet. Can we live in that world? Robinson says we can. I think so too. My idea is to take KSR’s world and tweak it a bit to meet our requirements, Charlie’s and mine. Of course, I’ve already read and blogged about New York 2140, but Bryan Alexander, futurist and educational consultant, has just kicked off a group reading. I figure that’s a good way for me to see what others think about the future.
This kicked off a series of posts on Musk, the simulation argument, and the Singularity. I’ll likely return here from time to time.
Joe Rogan’s reality club
On Thursday I returned to my interest in Joe Rogan with a long post, Joe Rogan and Joey Diaz call “Bruce Lee vs. Chuck Norris” – a rough transcription of their conversation. The title tells the story. I took a ten minute conversation that Rogan had with his buddy, Joe Diaz, about a scene from a classic martial arts film. Why’d I do that? Because I’m interested in what Rogan does and how he does it. Conversation’s his medium. The next step is to go through the conversation and comment on it, like I did with a paragraph from Heart of Darkness.
I don’t know when I’ll get around to this. Or even if I will. But I really should, shouldn’t I? And then I can wrap up my Rogan posts into another working paper.
Computational Lit Crit
Later on Thursday I published a long post on Michael Gavin’s recent article, Vector Semantics, William Empson, and the Study of Ambiguity. This first post centered on a famous memorandum, Gavin 1.1: Warren Weaver (1949) and statistical semantics. I’ve got two more posts planned for this series:
- Gavin 1.2: Warren Weaver 1949 and compositional semantics
- Gavin 2: Comments on a passage from “Paradise Lost”
Those posts are in an advanced stage of planning and an early stage of drafting. I hope to have Gavin 1.2 up in a day or three, to be followed by Gavin 2 and day or three later. Then I’ll assemble them into a working paper, post it, and then set about turning it into a paper for submission to an appropriate journal, perhaps Cultural Analytics.
The idea is to compare and contrast three distinct approaches to meaning, traditional “close-reading”, statistical semantics (which is well known in the digital humanities), and what I’m calling compositional or constructive semantics, which is not so well-known. Compositional semantics is what I did my doctoral work on. It’s well developed in cognitive science, but also in computational narratology, and computer gaming. Once I’ve got all three on the table (in Gavin 2) I can make a distinction between close reading on the one hand, and statistical and compositional semantics on the other. Close reading is about meaning, and meaning is ontologically subjective (in Searle’s sense). But statistical and compositional semantics are not. The exist in the object realm; they objectify meaning. Close reading is validated through ethical arguments; it is a tool of ethical criticism.
Statistical and compositional semantics are somewhat different and I’ve not yet figured out just how to talk about them. For the moment, let’s say that statistical semantics are assessed with respect to truth. Within cognitive criticism statistical semantics may be used in the context of an argument that is basically about meaning.
Compositional semantics as well can be assessed as to its truth. But it also has engineering uses.
It’s complicated.
* * * * *
And I’ve got to keep all these balls in the air, Green Villain, scenarios for the future, Rogan, and cognitive criticism.
And the photographs. Took several hundred this week.
That’s a lot of work.
Addendum: Oh, I forgot! I've got to start blogging about the segment's of Nina Paley's Seder-Masochism. The first post will be about two segments, This Land is Mine, which is the first one Nina made and is the last one in the film and, God-Mother, one of the last segments she completed and first in the film.
* * * * *
Addendum: Oh, I forgot! I've got to start blogging about the segment's of Nina Paley's Seder-Masochism. The first post will be about two segments, This Land is Mine, which is the first one Nina made and is the last one in the film and, God-Mother, one of the last segments she completed and first in the film.
An unidentified bug
"whats the best comment youve found in code?"— Name cannot be blank (@p01arst0rm) July 27, 2018
me: pic.twitter.com/H1ujyeBL3y
Artificial Intelligence learns from neuroscience
Jamie Condliffe, Google’s AI Guru Says That Great Artificial Intelligence Must Build on Neuroscience, MIT Technology Review, July 20, 2017.
Currently, most AI systems are based on layers of mathematics that are only loosely inspired by the way the human brain works. But different types of machine learning, such as speech recognition or identifying objects in an image, require different mathematical structures, and the resulting algorithms are only able to perform very specific tasks.Building AI that can perform general tasks, rather than niche ones, is a long-held desire in the world of machine learning. But the truth is that expanding those specialized algorithms to something more versatile remains an incredibly difficult problem, in part because human traits like inquisitiveness, imagination, and memory don’t exist or are only in their infancy in the world of AI.In a paper published today in the journal Neuron, Hassabis and three coauthors argue that only by better understanding human intelligence can we hope to push the boundaries of what artificial intellects can achieve.First, they say, better understanding of how the brain works will allow us to create new structures and algorithms for electronic intelligence. Second, lessons learned from building and testing cutting-edge AIs could help us better define what intelligence really is.
Here's the Neuron article:
Demis Hassabis, Dharshan Kumaran, Christopher Summerfield, Matthew Botvinick, Neuroscience-Inspired Artificial Intelligence, Neuron, Volume 95, Issue 2, p245–258, 19 July 2017.Abstract: The fields of neuroscience and artificial intelligence (AI) have a long and intertwined history. In more recent times, however, communication and collaboration between the two fields has become less commonplace. In this article, we argue that better understanding biological brains could play a vital role in building intelligent machines. We survey historical interactions between the AI and neuroscience fields and emphasize current advances in AI that have been inspired by the study of neural computation in humans and other animals. We conclude by highlighting shared themes that may be key for advancing future research in both fields.
Conclusions: In this perspective, we have reviewed some of the many ways in which neuroscience has made fundamental contributions to advancing AI research, and argued for its increasingly important relevance. In strategizing for the future exchange between the two fields, it is important to appreciate that the past contributions of neuroscience to AI have rarely involved a simple transfer of full-fledged solutions that could be directly re-implemented in machines. Rather, neuroscience has typically been useful in a subtler way, stimulating algorithmic-level questions about facets of animal learning and intelligence of interest to AI researchers and providing initial leads toward relevant mechanisms. As such, our view is that leveraging insights gained from neuroscience research will expedite progress in AI research, and this will be most effective if AI researchers actively initiate collaborations with neuroscientists to highlight key questions that could be addressed by empirical work.
The successful transfer of insights gained from neuroscience to the development of AI algorithms is critically dependent on the interaction between researchers working in both these fields, with insights often developing through a continual handing back and forth of ideas between fields. In the future, we hope that greater collaboration between researchers in neuroscience and AI, and the identification of a common language between the two fields (Marblestone et al., 2016), will permit a virtuous circle whereby research is accelerated through shared theoretical insights and common empirical advances. We believe that the quest to develop AI will ultimately also lead to a better understanding of our own minds and thought processes. Distilling intelligence into an algorithmic construct and comparing it to the human brain might yield insights into some of the deepest and the most enduring mysteries of the mind, such as the nature of creativity, dreams, and perhaps one day, even consciousness.



Friday, July 27, 2018
The interpretation of psychedelic experience is culturally bound
But even with the same substance, different cultures frame psychedelic experiences in different ways, leading to different experiences, as Andy Letcher argues in Shroom: A Cultural History of the Magic Mushroom (2006). The idea that psychedelics predictably lead to a unitive experience beyond time, space and culture is itself culture-bound – it’s the product of US culture, and the perennialism of Huxley, Dass, Ralph Waldo Emerson and others. Other cultures have framed psychedelics very differently.Indigenous American cultures have been taking psychedelic substances for millennia, and have developed their own frames for psychedelic drugs. The West rediscovered magic mushrooms in the 1950s when the amateur mycologist Robert Gordon Wasson travelled to Mexico in 1955 and took part in a mushroom ritual, guided by a Mazatec healing-woman called María Sabina. Wasson was sure he’d had a mystical experience, an encounter with the transcendental Divine, and this universal experience was at the root of all religions. He wrote up his experience in an article in Life magazine in 1957, which helped to instigate the psychedelic revolution.But Wasson’s interpretation of his experience was quite different to the typical Mazatec interpretation. Sabina said: ‘Before Wasson, nobody took the saintchildren [what Sabina called the mushrooms] only to find God. They were always taken for the sick to get well.’ Rather than a connection to cosmic consciousness or some such mystical goal beyond time and space, Mazatecs took (and occasionally still take) mushrooms to connect to local saints or local spirits, to help with local problems in their relationships, work or health. In anthropological terms, theirs is a horizontal transcendence, rather than the vertical individualist transcendence of Wasson, Huxley et al.
Culture is the small room you live in. Psychedelics are the door to the much vaster outside. If your culture shaped a need for a numinous experience, that's what you get. If your culture shaped a need for healing, that's what you get. https://t.co/qkWF6VEzq8— (((Howard Rheingold))) (@hrheingold) July 27, 2018
Elon Musk has created a private primary school for his kids and a few others
Not much is publically known about it. This, from 2015 sounds good:
Musk hired one of the teachers from the boys' school to help found Ad Astra, and the school now teaches 14 elementary-school-aged kids from mostly SpaceX employees' families. The CEO wanted his school to teach according to students' individual aptitudes, so he did away with the grade structure entirely. Most importantly, he says learning should be about problem solving."It's important to teach problem solving, or teach to the problem and not the tools," Musk said. "Let's say you're trying to teach people about how engines work. A more traditional approach would be saying, 'We're going to teach all about screwdrivers and wrenches.' This is a very difficult way to do it. A much better way would be, like, 'Here's the engine. Now let's take it apart. How are we gonna take it apart? Oh you need a screwdriver!'"
"Some people love English or languages. Some people love math. Some people love music. Different abilities, different times," he says. "It makes more sense to cater the education to match their aptitudes and abilities."
But unlike other schools, it doesn’t teach music and sports and language arts appear to be an afterthought, according to Ars. The reason? Musk thinks it’s more important for children to learn other topics when computers can take up the task of translating language in the future.
The school is called Ad Astra, "to the stars".





I think future computer tech will be amazing, but...
Back in 1800 the steam engine was king. The first steam locomotive was made in 1804; commercial success came in 1812. Those folks would have been dumbfounded at the Model T, not to mention a 1957 Buick Roadmaster, much less the Tesla Model S. In-freakin'-conceivable. And yet here they are.
It's going to be the same with computer tech. The stuff those folks will have 50, 100 years from now, unimaginable (even if the seas rise by 30 feet).
But you know what they won't have? That's right, they won't have super-intelligent computers. That's an idea grounded in current hopes and fears, not in anything like the deeper understanding of computing they'll have in 2118, And they'll probably understand the brain much better as well.
It's going to be the same with computer tech. The stuff those folks will have 50, 100 years from now, unimaginable (even if the seas rise by 30 feet).
But you know what they won't have? That's right, they won't have super-intelligent computers. That's an idea grounded in current hopes and fears, not in anything like the deeper understanding of computing they'll have in 2118, And they'll probably understand the brain much better as well.
Thursday, July 26, 2018
Cantometrics is heating up, a cross-cultural study of music
For example, relevant to the following recent news articles:https://t.co/Hsy24L9loPhttps://t.co/hIhOttbcSDhttps://t.co/fbPHRN1yzphttps://t.co/d0ufqEKGb2https://t.co/2Q9JEWkE6r— Pat Savage (@PatrickESavage) July 26, 2018
Gavin 1.1: Warren Weaver (1949) and statistical semantics [#DH]
Michael Gavin recently published a fascinating article in Critical Inquiry, Vector Semantics, William Empson, and the Study of Ambiguity [1], one that developed a bit of a buzz in the Twitterverse.
this is the essay pretty much everyone in cultural analytics/DH has been looking for— Richard Jean So (@RichardJeanSo) June 14, 2018
And stay for the fireworks at the very end! "…polemic of the kind that typically surrounds the digital humanities, most of which fetishizes computer technology in ways that obscure the scholarly origins …" https://t.co/tr1RiFNhVu— Ted Underwood (@Ted_Underwood) June 14, 2018
In the wake of such remarks I really had to read the article, which I did. And I had some small correspondence with Gavin about it.
I liked the article a lot. But I was thrown off balance by two things, his use of the term “computational semantics” and a hole in his account of machine translation (MT). The first problem is easily remedied by using a different term, “statistical semantics”. The second could probably be dealt with by the addition of a paragraph or two in which he points out that, while early work on MT failed and so was defunded, it did lead to work in computational semantics of a kind that’s quite different from statistical semantics, work that’s been quite influential in a variety of ways.
In terms of Gavin’s immediate purpose in his article, however, those are minor issues. But in a larger scope, things are different. And that is why I’m writing these posts. Digital humanists need to be aware of and in dialog with that other kind of computational semantics.
Warren Weaver 1949
In this post and in the next I want to take a look at a famous memo Warren Weaver wrote in 1949. Weaver was director of the Natural Sciences division of the Rockefeller Foundation from 1932 to 1955. He collaborated Claude Shannon in the publication of a book which popularized Shannon’s seminal work in information theory, The Mathematical Theory of Communication. Weaver’s 1949 memorandum, simply entitled “Translation” [2], is regarded as the catalytic document in the origin of MT.
He opens the memo with two paragraphs entitled “Preliminary Remarks”.
There is no need to do more than mention the obvious fact that a multiplicity of language impedes cultural interchange between the peoples of the earth, and is a serious deterrent to international understanding. The present memorandum, assuming the validity and importance of this fact, contains some comments and suggestions bearing on the possibility of contributing at least something to the solution of the world-wide translation problem through the use of electronic computers of great capacity, flexibility, and speed.The suggestions of this memorandum will surely be incomplete and naïve, and may well be patently silly to an expert in the field - for the author is certainly not such.
But then there were no experts in the field, were there? Weaver was attempting to conjure a field of investigation out of nothing.
I think it important to note, moreover, that language is one of the seminal fields of inquiry for computer science. Yes, the Defense Department was interested in artillery tables and atomic explosions, and, somewhat earlier, the Census Bureau funded Herman Hollerith in the development of machines for data tabulation, but language study was important too.
Caveat: In this and subsequent posts, I assume the reader understands the techniques Gavin has used. I am not going to attempt to explain them; he does that well in his article.


Joe Rogan and Joey Diaz call “Bruce Lee vs. Chuck Norris” – a rough transcription of their conversation
Two months ago I posted to 3 Quarks Daily about Joe Rogan’s podcast. I included three video clips, one of them a discussion about a scene from Way of the Dragon, a classic Hong Kong martial arts film from 1972. I chose that clip because it seemed to me at the time – I’d been watching The Joe Rogan Experience for two or three weeks – that it was dead center in Rogan’s universe of discourse. I’ve watched a lot more Joe Rogan since then and that clip still seems to exemplify his interests and his appeal.
So, it’s time to take another look at that clip. It’s from a podcast that originally aired on March 18, 2015. Joey “Coco” Diaz was his guest, along with Brian Redban, who’d been involved in the podcasts from the beginning. Diaz is a comedian who was born in Cuba and emigrated to the United States as a child. He’s a friend of Rogan’s and a frequent guest on the podcast. Jamie Vernon is behind the scenes mixing the audio, operating the cameras, and bringing up video clips for viewing.
The purpose of this post is simply to present a rough transcription of the conversation. I may, I really ought to, do another post where I comment on the conversation in some detail. But not right now. I just want to get it up there.
Reality maintenance
Why this clip? Because it is explicitly about reality maintenance, if you will. Reality maintenance is a routine feature of conversation. There are languages, for example, where one must inflect verbs to indicate how one knows the information being asserted. Did you see it yourself or did someone tell you about it? Is it something you have inferred or even something that happened in a dream? English is not such a language, but that kind of information is easily supplied. My point is simply that this kind of reality maintenance is all but automatic to conversation.
What’s transpiring in this Joe Rogan clip, and through out his podcasts, is more explicit. Quite often the point of a conversation is to work out, affirm, and share (a sense of) what is real, what’s really real. In this clip that is most obvious in those sections where Rogan is commenting on fighting technique or when Rogan or Diaz is commenting on some aspect of film technique. What happened, how, what’s important, why?
Fight technique is a major concern of Rogan’s. He is a martial arts practitioner and he has a continuing gig as commentator on UFC (Ultimate Fighting Championship) bouts. Real fights are one thing, something is at stake for the fighters, a competitive win, physical well-being, or even life itself. Fights in movies are quite different. Nothing’s at stake for the actors. And what’s at stake for the characters is being presented to an audience: what’s at state for them? Movie fights are often not physically realistic, presenting actions that wouldn’t or even couldn’t happen in a situation with real stakes for the fighters. How realistic is the fighting in this scene between Bruce Lee and Chuck Norris?
But there’s more at stake. After all, this is a fictional fight in which one man dies. Though the fight is a private one, there are no spectators, there are aspects to it that bespeak of ritual. Both Rogan and Diaz comment on that. This is about values, about ethics.
They also comment on film technique. The fight takes place in Rome in the remains of the Coliseum. That is, in the story being depicted in Way of the Dragon, that’s where the fight takes place. But that’s not actually where Lee and Norris were when they staged the fight. How can we detect that in the film? Moreover, Diaz calls our attention to the camera work at various points. He also remarks about the cats that show up as a motif in the scene. Feral cats live in the coliseum, and so their presence in the scene is an index that, yes, this IS (supposed to be) the Roman Coliseum. But the cats also punctuate the scene in an interesting way, providing a contrasting thematic resonance. Neither Diaz nor Rogan offer any analysis of this, but they’re clearly aware that it’s going on.
And then we have comments about the importance of this particular film, both in the history of martial arts film, but also, in Diaz’s case, its importance to children watching it, immigrant children in particular. What of Bruce Lee? Rogan and Diaz acknowledge and affirm his importance as a figure in the martial arts and in martial arts cinema and they make specific comments about what he does in the fight, Norris too.
Over the course of his podcasts Rogan is weaving a sense of the world; he is enacting the process of constructing a shared reality. That’s most obvious from his interest in conspiracy theories and psychedelic drugs, but it’s there in other discussions as well. Why else would he provide a list of books mentioned in the podcast, a list of his favorites, his recommendations, how to read more books, and why?
Conversational interaction
I’m just as interested in how the conversation unfolds. There are stretches where one person has the floor for 10, 20, seconds or more, there are other stretches where turns change in short phrases of a word or three, and still other sections where two or three voices overlap. How does that work?
We have a mixture of different modes of discourse. There’s a lot of referential language – about the film, the martial arts, whatever. But there are frequent interjections as the film gets exciting. Just as often Rogan or Diaz will use short phrases or even single words to direct one another’s (and our) attention to what is happening in the film. Various modes–referential, exclamation, attention-setting, will intermix within a two or three second interval. There are also segments where two or even three people will overlap very rapidly, without allowing for proper turn changes, or even talk simultaneously. And there are one or two places where Rogan will ask Jamie Vernon to stop the clip, or even replay a segment.
Except for a few relatively short segments where there audio is muddled, the conversation is easy to follow. And, in a measure, THAT’s the point of this exercise. We, us humans, do this kind of thing all the time. It’s natural for us. But remove yourself from the conversational forum and observe it as an outsider trying to figure out what these creatures are doing, then it becomes bewildering.
Transcription is a first step in figuring out what we do and how we do it.
Things shared by the simulation argument and superintelligence, a deconstruction
By simulation argument I mean the argument that suggests that we are living in a computer simulation created by a race of super-intelligent Orchestrators (my term).
 |
| The Orchestrator |
 |
| Malevolent Superintelligence |
Both arguments assume that what’s essential is sufficient computing capacity, CPU cycles and memory space.
capacity + magic = {superintelligence or simulation}
Let’s put the magic off to one side; I don’t care about that, though Mickey up there sure does. Magic’s what made his dream come true. And, alas, physical reality, in the form of water, is what crashed it.
Both arguments trivialize the physical world. As I argued yesterday, Bostrom’s argument is all about simulating minds. That’s his main and all-but-only concern. And of course, if you’re going to simulate human history, then you have to simulate minds. Can’t avoid it. He treats the physical world as, at best, an optional accessory for the minds. Big mistake.
The argument for superintelligence is somewhat different. But it tacitly assumes that a mind can be built directly (and, I might add, from the “outside”). That’s not how human minds are built. They’re built through a process of interacting with the environment (and they’re built from the “inside”), where the mind starts the minimal capacities, devoted mostly to feeding and human interaction, an emerges through interacting with the world as more and more capacity (neurons) mature and brought “on line”. A robust physical environment is thus critical to development. Interaction with the external (physical) world is where the mind gets so-called “common sense” knowledge, the missing ingredient in AI.
Now, the thing is, one thing my teacher, David Hays (computational linguist), emphasized to me, is that computing, real computing not abstract theory, is a physical process. It takes place in time and requires physical memory. Of course the simulationists and superintelligencers make that central to their argument; in deed that’s almost the only thing in their argument that’s explicit. The rest is magic. Neither Hays nor I ever believed that the physicality of computing is somehow apart from physicality in general. Not so with the Supers.
Are they stuck in Never Never Land?
And just why, you might ask, is this a deconstruction. Not because I argue against the Supers. Alas, that's not what deconstruction is, though that's what the word has devolved to. No, it's a deconstruction because I take a central feature of both arguments, the availability of physical capacity for computing, and show that the arguments work through a denial of physicality in a larger sense.
* * * * *
And just why, you might ask, is this a deconstruction. Not because I argue against the Supers. Alas, that's not what deconstruction is, though that's what the word has devolved to. No, it's a deconstruction because I take a central feature of both arguments, the availability of physical capacity for computing, and show that the arguments work through a denial of physicality in a larger sense.
Wednesday, July 25, 2018
My problem with the simulation argument: It’s too idealist in its assumptions (all mind, no matter)
By “simulation argument” I mean the argument that it’s highly likely that we’re not real people. Rather, we’re just creatures in a computer simulation being run by a highly advanced civilization...somewhere...up/out there.
The idea was first advanced, I believe, by Nick Bostrom in a well known argument, Are You Living in a Computer Simulation? (Philosophical Quarterly, 2003, vol. 53, no. 211, 243-255). I don’t know when I first read it, but certainly not when it was published. It creeped me out. And then I set it aside, returning every now and then, but no longer being creeped out.
I don’t believe it.
There are subtleties in just what Bostrom’s proposing. It’s not as simple as: “We’re living in a simulation and here’s why.” It’s couched in a trichotomy, one of which is supposed to be true. We can set that aside.
The basic argument is about: 1) the amount of computing power an advanced civilization will be able to create, and 2) the amount of computing power needed to simulate a human mind. To simulate a historical evolution one must, of course, simulate a bunch of minds. Bostrom takes that into account and says its doable. While I’m by no means sure that those future masters, call them the Orchestrators, will be able to simulate minds, let’s set that aside.
What I’m wondering is how much of the environment has to be simulated? Bostrom isn’t clear on that (p. 5): “If the environment is included in the simulation, this will require additional computing power – how much depends on the scope and granularity of the simulation.” So, there’s some possibility that we might not have to include the environment. I don’t believe that for a minute. In any event, Bostrom has some remarks about simulating the environment (p. 5):
Simulating the entire universe down to the quantum level is obviously infeasible, unless radically new physics is discovered. But in order to get a realistic simulation of human experience, much less is needed – only whatever is required to ensure that the simulated humans, interacting in normal human ways with their simulated environment, don’t notice any irregularities. The microscopic structure of the inside of the Earth can be safely omitted. Distant astronomical objects can have highly compressed representations: verisimilitude need extend to the narrow band of properties that we can observe from our planet or solar system spacecraft. On the surface of Earth, macroscopic objects in inhabited areas may need to be continuously simulated, but microscopic phenomena could likely be filled in ad hoc.
Bostrom asserts that “whatever is required to ensure that the simulated humans [...] don’t notice any irregularities” is sufficient. Is that sufficient? Just what does it mean? That’s not at all clear to me.
Consider something that actually happened in earth’s history in the nineteenth century. In 1883 a volcanic island in Indonesia, Krakatoa, erupted violently. It was heard over 2000 miles away and global temperatures were depressed by 1.2 degrees Celsius. Temperatures didn’t return to normal until 1888.
How would such an event come about in a Bostrom simulation? If the Orchestrators know they want such an event in a given simulation, well then they can take measures to ensure that the simulated people have the appropriate sensations. It is not at all obvious to me, however, that a Bostrom simulation would have sufficiently rich geodynamics so that such an event would arise ‘naturally’, from within the simulation, rather than being introduced from the outside by the Orchestrators. And that’s cheating, no?
Bostrom seems to think that, if the Orchestrators need to simulate the environment at all, that is ONLY because they have to provide sensations and perceptions for the simulated people. He sees no need to provide the non-human world with its own robust dynamics.
Has Bostrom considered the requirements of starting a simulation without any humans at all so that, in time, humans could evolve in that world? What would such a simulation require–the impossible “down to the quantum level” simulation? If a Bostrom simulation can’t run a world within which humans can emerge, then do we have any reason to believe that it would provide an adequate simulation of human history.
Consider this (p. 5): “What you see through an electron microscope needs to look unsuspicious, but you usually have no way of confirming its coherence with unobserved parts of the microscopic world.” Will bacteria and viruses exist only as suitably simulated images in simulated electron microscopes? Where will simulated disease come from? What about the microbiome so essential to real life? Are Bostrom zombies only feeling occasional sensations of digestion without any simulated digestion taking place?
It seems to me that Bostrom’s Orchestrators are providing only simulated sensations and perceptions. There are no simulated physical dynamics. There is no world at all.
* * * * *
See this post as well: Two silly ideas: We live in a simulation & our computers are going to have us for lunch.

Musk vs. Bezos: very different tech-driven visions of the future
Jeff Bezos is the wealthiest man in the world and is in the process of converting his "Amazon lottery winnings" (his term) into a space transportation infrastructure so that future generations can innovate space-based business on the cheap. He envisions a trillion people inhabiting the solar system. Nor is he worried about the emergence of an evil artificial super-intelligence that's an existential risk to humanity. In contrast, THAT's Musk's greatest worry. At the moment his SpaceX is probably ahead of Bezos's Blue Origin in the space race, but that's a loooong race, long. He sees man-in-space primarily as insurance against Earth-failure, which Bezos thinks silly/unlikely. Musk's into sustainable energy as well, Tesla (& its Solar City subsidiary). It would be interesting to seem them discuss these issues face-to-face. Who knows, maybe they have already.
Still, here's a pair of videos, one of each, that lay out some of the issues.
But, you know, their imaginations seem to in in thrall to bigness – Bezos perhaps more than Musk – and that's a problem. & they'd don't say a thing about music, dance, painting, quilt-making...
Tuesday, July 24, 2018
On the "thagomizer" trail
The interesting thing is that instance is in mathematics where every other example I've seen retains Larson's original usage. So how'd the mathematicians get a hold of it? On a hunch, I looked at the paper and spotted this https://t.co/RXz5m6PKfu— Bill Benzon (@bbenzon) July 24, 2018
I found out about the mathematics paper from a comment on Jerry Coyne's blog (by user Jair), which is where I saw the tweet containing the Gary Larson cartoon.
The Democratic party: "A Fabian retirement home on visiting day"
quoth @zenpundit >The face of the Democratic Party is: three old white women, an even older white socialist dude and a 28 year old socialist woman of color. The Party is a Fabian retirement home on visiting day— hipbonegamer (@hipbonegamer) July 24, 2018
On the tension between cooperation and coordination
Connor Wood, Catherine Caldwell-Harris, and Anna Stopa (2018). “The Rhythms of Discontent: Synchrony Impedes Performance and Group Functioning in an Interdependent Coordination Task,” Journal of Cognition and Culture 18 154-179. DOI: 10.1163/15685373-12340028.
Abstract: Synchrony has been found to increase trust, prosociality and interpersonal cohesion, possibly via neurocognitive self-other blurring. Researchers have thus highlighted synchrony as an engine of collective identity and cooperation, particularly in religious ritual. However, many aspects of group life require coordination, not merely prosocial cooperation. In coordination, interpersonal relations and motor sequences are complementary, and leadership hierarchies often streamline functioning. It is therefore unclear whether synchrony would benefit collaborative tasks requiring complex interdependent coordination. In a two-condition paradigm, we tested synchrony's effects on a three-person, complex verbal coordination task. Groups in the synchrony condition performed more poorly on the task, reporting more conflict, less cohesion, and less similarity. These results indicate boundary conditions on prosocial synchrony: in settings that require complex, interdependent social coordination, self-other blurring may disrupt complementary functioning. These findings dovetail with the anthropological observation that real-world ritual often generates and maintains social distinctions rather than social unison.
Here's a blog post at Patheos explaining the work. From the post:
So the findings seem pretty clear: rhythmic synchrony dissolves boundaries between participants, releases pain-numbing, pleasure-causing endorphins, and makes people feel more cooperative and close to one another. Given that many religious and cultural rituals aim at building social bonds, it make sense that many rituals include synchrony. Hence, thinkers such as the late historian William McNeill have argued that religious rituals may even have their evolutionary roots in rhythm and dance.But, are religious rituals really so full of synchrony? And is synchrony always a good thing?If you go to a mosque and watch (or take part in) one of the five daily salat prayer services, you’ll definitely see synchrony. After the end of the azan call, worshipers take part in cycles of highly synchronized kneeling, prostration, and standing, vocally guided by the imam. But you’re also likely to see people getting up out of sync, wandering around, coming in late, leaving early. Sometimes the imam doesn’t guide the prayer audibly, so the faithful are left to their own rhythms. In that case there’s often not much coordination between different people at all.Similarly, in a Catholic Mass, periods of conspicuous group synchrony – such as hymn singing or recitation of the Lord’s Prayer – alternate with extensive times when people are doing different things. For example, during the Eucharist itself, people shuffle up and down the aisles to reach the altar, receive their wafers and wine one at a time – not simultaneously – and then wander back to their seats at their own pace. It can look positively disorganized.Beyond the context of ritual, a whole lot of real-world, secular activities don’t feature much synchrony at all. When workers are building a skyscraper, the concrete pourers are working at a different pace relative to the crane operator, the window installers, and the steelworkers. If they all worked at one single, constant rhythm, they couldn’t do their unique, specialized jobs, and the building wouldn’t get built.
The post continues: "My lab team wanted to explore this intersection of convergent (identical) and complementary (different but coordinated) behaviors in a novel setting." Here's what they found:
As described above, previous studies had mostly shown that synchrony has positive effects on group dynamics. But in our study, we found the opposite. Not only did groups in the synchrony condition perform worse on the main task – they composed fewer and less-complex sentences than groups that had swung pendulums out-of-sync – but they also reported more “procedural conflict,” or interpersonal clashes about how to best succeed at the sentence task.What’s more, groups in the synchrony condition reported feeling less in-group similarity, and a reduced sense of belonging to a tight collective, than subjects in the asynchrony condition. Overall, it almost seemed as if being in a task-oriented context reversed the normal, positive effects of synchrony.
And so:
But meanwhile, there’s good reason to infer that, while rhythm and synchrony might make people feel more cooperative, they might not be helpful in contexts that require intricate coordination and leadership, since such tasks seem to call for differentiated practical roles, not total social unison.
Subscribe to:
Posts (Atom)