In the first post in this series (Gavin 1.1: Warren Weaver (1949) and statistical semantics) I suggested that what Gavin [1] calls “computational semantics” might more accurately be called “statistical semantics” and went on to offer some remarks about statistical semantics using Warren Weaver’s 1949 memorandum, “Translation” [2], as my starting point. The purpose of this post is to offer some remarks about a different body of work in semantics, again making reference to Weaver’s 1949 memorandum.
As far as I know there is no standard term for this other body of work that would differentiate it from statistical semantics while still indicating that it is computational in nature. I have no interest in policing anyone’s usage of language and realize that terms have life of their own. Still, as a practical matter, I need to make a distinction and so, for the purposes of this post, I will use the term “computational semantics” for this other body of work.
This post will not be quite so straightforward as that first one. First I want to say a bit about how the collapse of funding for machine translation (MT) was followed by work on the problem of language understanding. That’s a story that Gavin didn’t tell, presumably because it isn’t relevant to the substance of his essay. But I’d have been a bit happier if he’d at least mentioned that the research had been undertaken.
In the next section I return to Weaver’s memo, where he mentions having talked with one Dr. Richens. That will bring us back to Gavin’s story by way of Cambridge Language Research Unit (CLRU) founded by Margaret Masterman. From there I move to work I had participated in during my graduate study, the use of computational semantics in the study of abstract concepts and of topic analysis. I will give the last word to Martin Kay, one of the grand old men of computational linguistics.
The over all effect of this post is to take Gavin’s article as a framework within which I tell a story he glossed over. In the next post I will take a look at his discussion of a passage from Milton using statistical semantics and juxtapose it against work I did on Shakespeare’s Sonnet 129 using computational semantics.
From MT to language understanding
As Gavin has indicated, research into MT was catalyzed by Weaver’s memorandum and funded largely by the Defense Department (pp. 649-650). By the early 1960s achievements lagged far behind expectations and the federal funding dried up. As Victor Yngve noted (quoted in Brian Lennon [3] p. 143):
[w]e have come face to face with the realization that we will only have adequate mechanical translations when the machine can “understand” what it is translating and this will be a very difficult task indeed.
And that, understanding, is what many researchers decided to tackle, though under the broader rubric of computational linguistics. They were joined by researchers in AI and cognitive science.
Gavin leaves MT at this point and turns to the emergence of statistical semantics and to Margaret Masterman, whom I’ll mention in the next section. But I want first to take a brief look at computational semantics. The body of relevant work is vast and I have no intention of attempting to indicate the whole [4]. But I want to look at one seminal system.
In the late 1960s Terry Winograd constructed the SHRDLU system while a graduate student at MIT [5]. Like most AI systems it was designed to work in a very restricted world, in this case, a world of blocks. The user interacts with the system using natural language, typing commands and making queries, and viewing the state of the blocks world on a graphics terminal. Here is a fragment of typical dialog:
Person: Pick up a big red block.Computer: OK.Person: Grasp the pyramid.Computer: I DON'T UNDERSTAND WHICH PYRAMID YOU MEAN.Person (changing their mind): Find a block which is taller than the one you are holding and put it into the box.Computer: BY "IT", I ASSUME YOU MEAN THE BLOCK WHICH IS TALLER THAN THE ONE I AM HOLDING.Computer: OK.Person: What does the box contain?Computer: THE BLUE PYRAMID AND THE BLUE BLOCK.Person: What is the pyramid supported by?Computer: THE BOX.Person: How many blocks are not in the box?Computer: FOUR OF THEM.Person: Is at least one of them narrower than the one which i told you to pick up?Computer: YES, THE RED CUBE.Person: Is it supported?Computer: YES, BY THE TABLE.Person: Can the table pick up blocks?Computer: NO.Person: Can a pyramid be supported by a block?Computer: YES.Person: Can a pyramid support a pyramid?Computer: I DON'T KNOW.Person: Stack up two pyramids.Computer: I CAN'T.Person: Will you please stack up both of the red blocks and either a green cube or a pyramid?Computer: OK.
Primitive? Yes. But at the time it was a remarkable achievement. The point is simply that the user could interact with the machine using natural language, rather than a computer language, and the computer would respond appropriately. The machine understands language in the sense that it responds appropriately to natural language discourse, albeit of a very limited range. That was new.
From Weaver 1949 to Masterman and semantic nets
It is time to return to Weaver’s memorandum, where we find this passage, which is of interest because of a person it mentions:
On May 25, 1948, W.W. visited Dr. Booth in his computer laboratory at Welwyn, London; and learned that Dr. Richens, Assistant Director of the Bureau of Plant Breeding and Genetics, and much concerned with the abstracting problem, had been interested with Dr. Booth in the translation problem. They had, at least at that time, not been concerned with the problem of multiple meaning, word order, idiom, etc.; but only with the problem of mechanizing a dictionary.
Richard H. Richens became affiliated with the Cambridge Language Research Unit where he proposed semantic nets in 1956, the first one to do so [6].
The CLRU had been founded by Margaret Masterman, who had studied with Wittgenstein. In addition to work on MT, she also experimented with computer-generated haiku [7]. Independently of her work in where she showed the Thomas Kuhn used the concept of paradigm in 21 different senses in his famous The Structure of Scientific Revolutions [8]. But then a word with 21 different senses is an ambiguous word and it is in that context, ambiguity, that Gavin is interested in her work. In particular, she was interested in “developing semantic dictionaries that organized words under larger headings, much like a thesaurus” (p. 653).
Gavin reproduces the following semantic network from her work on thesauruses:
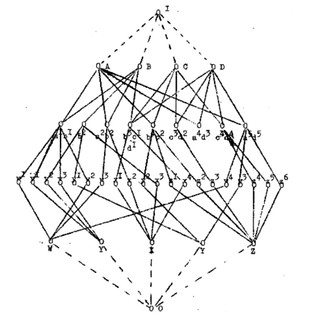
That network has the form of a lattice which, incidentally, is the form that Lévi-Strauss proposed for the “totemic operator” in The Savage Mind (1966, p. 152).
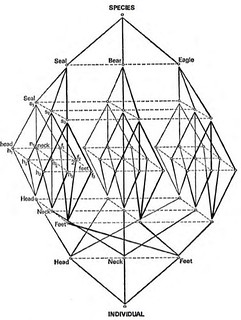
I mention this, not to suggest any influence one way or the other–the lattice is a well-known mathematical object, but as an indicator of the intellectual spirit of the times. In the 1970s Lévi-Strauss would collaborate with an American computer scientist, Sheldon Kline, on a computational model of myth [9].
But just what IS a semantic (or alternatively, cognitive) net? Here’s a simple network:
That is a mathematical object called a directed graph. When used to represent a conceptual structures, the nodes are taken to represent concepts while the edges (also called arcs or links) between the nodes represent relations between concepts. In such a system, the meaning of a concept (a node) is a function of its position in the network.
This is a small fragment from a cognitive network:
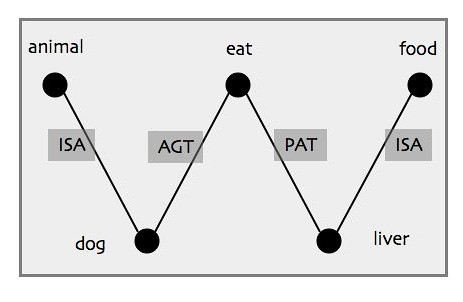
The labels on the edges specify the kind of relation that obtains between the nodes at either end of the edge. Thus dog is an agent (AGT) participant in an act of eating while liver is an inert (NRT) participant in that act: dog eats liver. Similarly, dog is a variety (VAR) of animal; liver is a variety (VAR) of food. Much of the work in devising a cognitive network is figuring out what kinds of nodes and edges to use.
Abstraction and Topic Analysis
Many cognitive scientists used a network notation, my teacher, David Hays among them. Hays had headed the MT program at the RAND Corporation in the 1950s and 1960s. By the time I came to study with him in the 1970s his interest became focused on semantics.
In 1973 Hays had proposed that abstract concepts got their meaning from stories [10]. Charity was the standard example. What is charity? Charity is when someone does something nice for someone else without thought of reward. Consider the following diagram:
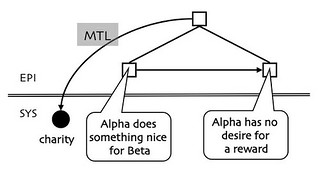
Note, first of all, that the network is divided into a systemic network (SYS) at the bottom and an episodic network (EPI) at the top. That was a fairly standard distinction at the time, where the systemic network is roughly like a dictionary while the episodic network is roughly like an encyclopedia. Those square episodic nodes are called modalities and they anchor things and events in space and time. The two speech balloons, of course, are just a quick and dirty stand-ins to represent networks of systemic concepts. In this case, someone (Alpha) does something nice for someone else (Beta) and subsequently has no desire for a reward. It is these two things conjoined together – the modality at the top – that constitute the charitable act.
Notice that the episodic pattern is linked back to a node, labeled charity, in the systemic network. The edge that does that is said to be a metalingual edge (MTL), named after the metalingual function of language as defined by Roman Jakobson [11]. Hays called this mechanism metalingual definition. Thus defined, charity is a function of the entire story, not of any one element in the story. One recognizes acts of charity by identifying stories that have the appropriate elements in the appropriate arrangement.
Hays used the concept of metalingual definition to analyze various concepts of alienation used in the social sciences [12]. One graduate student, Mary White, had done a dissertation where she investigated the belief system of a contemporary millenarian community and used the model to analyze and describe those beliefs [13]. Another student, Brian Phillips, investigated stories about drownings with a program written in SNOBOL and running on a CDC 6400 mainframe – CDC (Control Data Corporation) no longer exists.
Phillips was interested in the difference between stories that were merely narratives and stories that had thematic content. He chose tragedy as his theme. What is tragedy? Tragedy is when “someone does a good act that results in his death” [14]. Phillips tested the system by analyzing a number of stories. Most had been elicited from students taking linguistics and English classes, but he found at least one in The New York Times. The system had no parser, only semantics; input was thus expressed in a cognitive formalism rather than using raw text.
Consider the following two examples:
(Story 4) A body was found early yesterday at the foot of the Mango River, near Clubsport. The body is believed to be that of Jose Gepasto. It seems as if Mr. Gepasto’s car made a wrong turn on the highway and plunged into the water.
(Story 22) DF, 43 years old, of Queens, drowned today in MB reservoir after rescuing his son D, who had fallen into the water while on a fishing trip at TF, near here, the police said.
Story 22 – the story from The New York Times, with names redacted – exhibits the pattern of tragedy, a man died subsequent to rescuing his son. Story 4 does not.
Notice that in reading Story 4 we assume that Mr. Gepasto must have been inside his car and that, because the car fell into the water, he must have fallen too. The story doesn’t explicitly say that, nor does it say that he drowned. We infer such things because it is, well, you know, common sense. Everyone knows that. But not the computer; such knowledge must be hand-coded into the system’s knowledge base. A large group of researchers has devoted considerable effort to investigating the structure of so-called common sense reasoning. That work is ongoing.
Two kinds of computational semantics
We now have two kinds of computational semantics on the table. One of them, statistical semantics, is computational in the sense that computation is required to conduct the work. Statistical semantics does not, however, use computation as a process for understanding or creating texts. That is what this other kind of computational semantics does. We can put this in terms of models. Statistical semantics models the distribution of words in a corpus; it is fundamentally static. Computational semantics models language process, understanding, production, or both; it is fundamentally and irreducibly temporal.
It is a matter of no small interest that statistical semantics, and statistical techniques generally, have come to dominate practical language technology, including translation. It is a matter of no small interest that statistical semantics, and statistical techniques generally, have come to dominate practical language technology, including translation. In contrast, and understanding of semantics as a computational processes, whether it a machine or in the human mind, remains a topic for research. I am tempted to say that we both know more than we did in the 1970s and we know less. Surely we know more, but how could we also know less? As the circle of our knowledge grows larger, so does the area of ignorance outside that circle. That suggests that, if and when we finally think we know it all, we’ll take one more step and realize that we know nothing.
Let us close this circle with the words of Martin Kay. Kay apprenticed with Margaret Masterman at the CLRU in the 1950s. In 1951 David Hays hired him to work with the RAND group in MT. He went on to a distinguished career in computational linguistics at the University of California, Irvine, the Xerox Palo Alto Research Center, and Stanford. In 2005 the Association for Computational Linguistics gave him a Lifetime Achievement Award. On that occasion he looked back over his career and made some observations about the relative merits of statistical and symbolic approaches to MT. His fourth point concerned ambiguity ([15] pp. 12-13)
This, I take it, is where statistics really come into their own. Symbolic language processing is highly nondeterministic and often delivers large numbers of alternative results because it has no means of resolving the ambiguities that characterize ordinary language. This is for the clear and obvious reason that the resolution of ambiguities is not a linguistic matter. After a responsible job has been done of linguistic analysis, what remain are questions about the world. They are questions of what would be a reasonable thing to say under the given circumstances, what it would be reasonable to believe, suspect, fear or desire in the given situation. [...] As a stop-gap for the time being, [statistical approaches] may be as good as we can do, but we should clearly have only the most limited expectations of it because, for the purpose it is intended to serve, it is clearly pathetically inadequate. The statistics are standing in for a vast number of things for which we have no computer model. They are therefore what I call an “ignorance model”.
References
[1] Michael Gavin, Vector Semantics, William Empson, and the Study of Ambiguity, Critical Inquiry 44 (Summer 2018) 641-673: https://www.journals.uchicago.edu/doi/abs/10.1086/698174
[2] Warren Weaver, “Translation”, Carlsbad, NM, July 15, 1949, 12. pp. Online: http://www.mt-archive.info/Weaver-1949.pdf
[3] Brian Lennon, “Machine Translation: A Tale of Two Cultures,” in A Companion to Translation Studies, ed. Sandra Bermann and Catherine Porter (Malden, Mass., 2014), pp. 135–46.
[4] David Hays and I reviewed some of that work in “Computational Linguistics and the Humanist”, Computers and the Humanities, Vol. 10. 1976, pp. 265-274. https://www.academia.edu/1334653/Computational_Linguistics_and_the_Humanist
[5] Winograd maintains a webpage devoted to SHRDLU. There you can download the original MIT tech report and access various instantiations of the SHRDLU system. That page also has the dialog that I excerpt in this post. URL: http://hci.stanford.edu/~winograd/shrdlu/
[6] Semantic network, Wikipedia, accessed July 30, 2018, https://en.wikipedia.org/wiki/Semantic_network
[7] Masterman, M. (1971) “Computerized haiku”, in Cybernetics, art and ideas, (Ed.) Reichardt, J. London, Studio Vista, 175-184. I discuss this work in a post, Free Play and Computational Constraint in Lévi-Strauss, New Savanna, February 15, 2015, https://new-savanna.blogspot.com/2015/02/free-play-and-computational-constraint.html
[8] Masterman, Margaret (1970) [1965], “The Nature of a Paradigm”, in Lakatos, Imre; Musgrave, Alan, Criticism and the Growth of Knowledge, Proceedings of the 1965 International Colloquium in the Philosophy of Science, 4 (3 ed.), Cambridge: Cambridge University Press, pp. 59–90, ISBN 9780521096232
[9] Klein, Sheldon et al. Modelling Propp and Lévi-Strauss in a Meta-symbolic Simulation System. in Patterns in Oral Literature, edited by H. Jason & D. Segal, World Anthropology Series, The Hague: Mouton, 1977.
[10] Hays, D.G.: The Meaning of a Term is a Function of the Theory in Which It Occurs. SIGLASH Newsletter 6, 8-11 (1973).
[11] Jakobson, R.: Linguistics and Poetics. In: Sebeok, T (ed.): Style in Language, pp. 360-377. The MIT Press, Cambridge, MA (1960).
[12] Hays, D.G.: On “Alienation”: An Essay in the Psycholinguistics of Science. In: Geyer R.R., Schietzer, D.R. (eds.): Theories of Alienation. pp. 169-187. Martinus Nijhoff, Leiden (1976). https://www.academia.edu/9203457/On_Alienation_An_Essay_in_the_Psycholinguistics_of_Science
[13] White, M.: Cognitive Networks and World View: The Metaphysical Terminology of a Millenarian Community. Ph. D. Diss. State University of New York at Buffalo (1975).
[14] Phillips, B.: A Model for Knowledge and Its Application to Discourse Analysis, American Journal of Computational Linguistics, Microfiche 82, (1979).
[15] Kay, M.: A Life of Language. Computational Linguistics 31(4), 425-438 (2005). http://web.stanford.edu/~mjkay/LifeOfLanguage.pdf
No comments:
Post a Comment