Andrew Goldstone and Ted Underwood , “The Quiet Transformations of Literary Studies: What Thirteen Thousand Scholars Could Tell Us”, New Literary History 45, no. 3, Summer 2014. Website: http://andrewgoldstone.com/blog/2014/05/29/quiet/
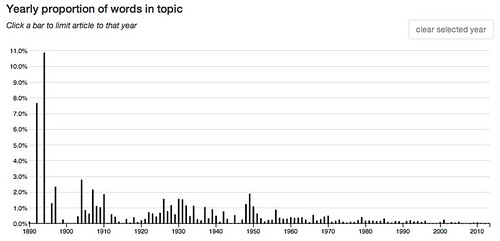
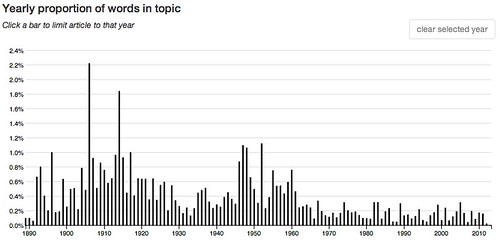
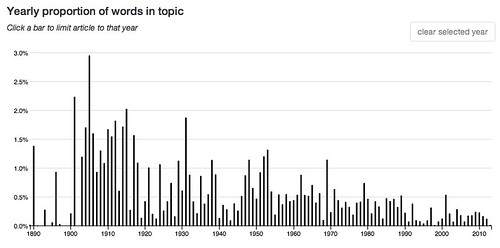
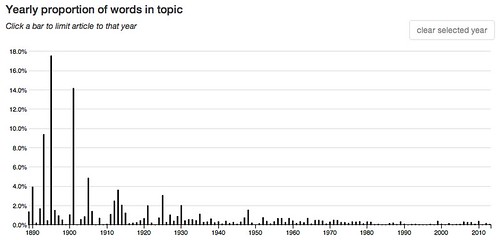
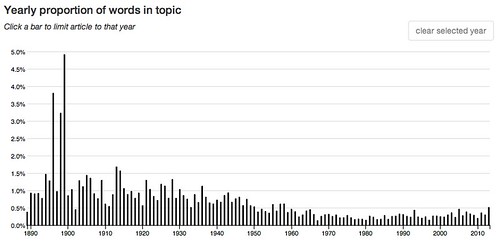
A week or so ago when I was examining the topic model Goldstone and Underwood used in their study of the shifting interests of academic literary critics I became curious about the topics that accounted for the largest number of word tokens in the entire corpus. I’d noticed one, for example, that accounted for 8.7% of the tokens. What’s that about? What about the next highest three topics?
So I looked them up and here they are, the top four arranged in that order, from top to bottom, but without any information to identify what’s in the topics:
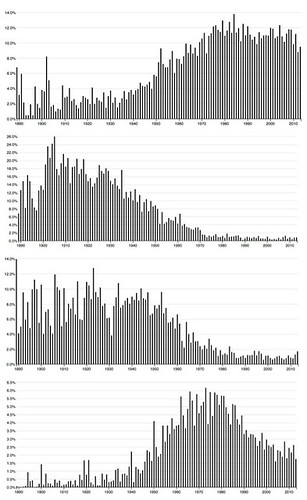
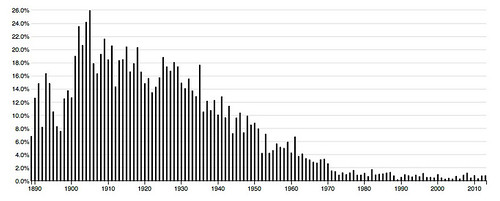
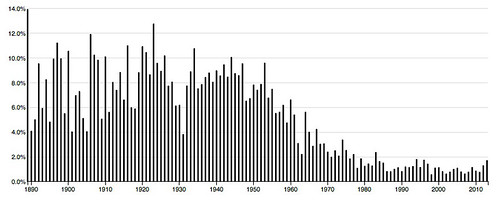
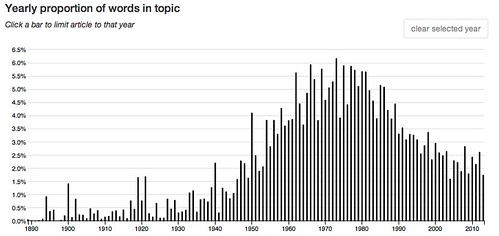
These charts are quite different. The middle two are skewed to the left and the top and bottom one are skewed to the right, the though bottom one, while generally to the right, is strongest toward the center.
One would expect them to be quite different. But they’re not. This table lists the words in the topic along with the totals for the corpus:
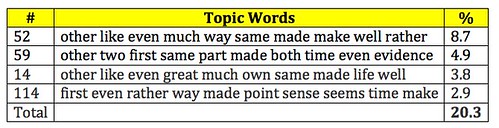
Even a casual look at those words, only the top 10 for each topic, reveals quite a bit of overlap. This table gives more detail:
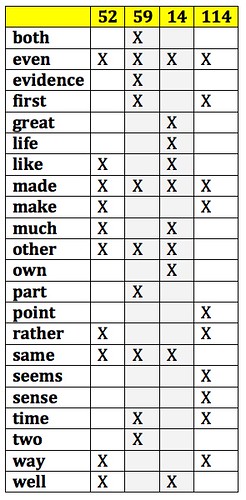
We’ve got only 22 different words. Two of them, “even” and “made”, are present in all four topics while two others, “other” and ”same”, are present in three topics. If these topics are so apparently similar, why are they distributed so differently in time?
Curious about this, I sent an email to Ted Underwood that included an earlier version of this document, suggesting that the difference has to be in the words at the middles and the bottom ends of the topics, which cannot be easily examined in the online presentation. I noted:
Those top ten words seem to be semantically neutral, sort of "connector" words. They don't identify any substantive intellectual interests. These topics must somehow be complements to those topics which show strong thematic interests concentrated either early in the discipline's history, or late.
Here’s Underwood’s reply:
I think you're really right about the problem here. These large topics are representing something of historical significance, but the standard way of labeling them doesn't reveal what.One thing I tried (though it didn't make it into the final article) was labeling topics by selecting words that are prominent in the topic and that also correlate with its trajectory over time. That gets you down below the neutral "connector" words at the top of the list, and reveals what it is that's changing over time. I believe that labeling strategy makes these big "glob topics" a lot more interpretable. It works well with smaller topics too. But this is also a kind of an ad hoc trick, and we didn't want to complicate the story in the article.
So, let’s think about this for a minute. If we look at the topics that skew to the right (that is, the present) in these charts, they tend to be Theory-laden and are heavily about society and politics, as Goldstone and Underwood pointed out – I’ve presented a few of them below. Those that skew right (the past), are quite different in character – I’ve presented some of them as well.
The topics in these two groups, right and left skewing, are all much smaller than these four “megatopics”. The top ten words in those megatopics could easily be used in any of these much smaller, but skewed topics. Now if we think about how language is used, it would seem to me that these megatopics each represent relatively large quasi-related groups of smaller topics, but the semantic identity of these topics, as I’ve already said, is visible only at the middle or bottom of the word distribution for each topic.
It would be interesting to take a look and see what we’ve got. A given word can, of course, appear in more than one topic. And a word that appears in multiple topics may be very important in some, relatively unimportant in others, and of middling importance in still others. There’s an overall conceptual “economy” here that we’re not looking at. What tools would we need to do that?
There are three more sections in this post. In the next section I repeat the top four, this time with the top ten words associated with each topic. Then I present six left-skewed topics followed by four right-skewed topics. For each topic I give the topic number in bold and the top ten topic words in italics.
Four Largest Topics
52: other like even much way same made make well rather – 8.7 % of words in the corpus.
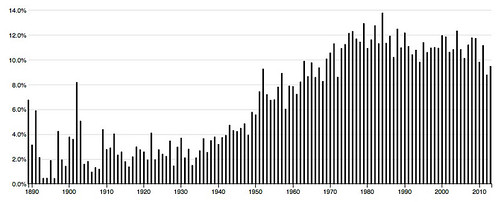
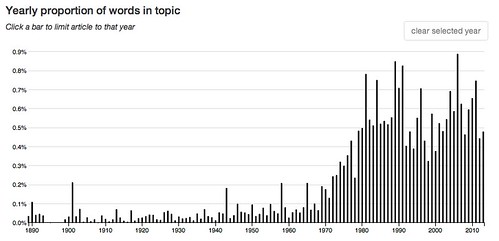
59: other two first same part made both time even evidence – 4.9 % of words in the corpus.
14: other like even great much own same made life well – 3.8 % of words in the corpus.
114: first even rather way made point sense seems time make – 2.9 % of words in the corpus.
Skewed Left
These topics were popular in the earlier years of the profession.
3: old beowulf english ic mid swa pe poet ond Grendel
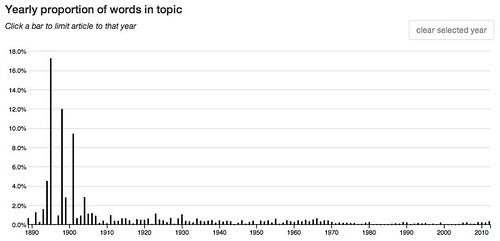
11: mas lope spanish pues quien see amor comedia vn spain
24: german goethe schiller lessing friedrich wilhelm germany herder schlegel heinrich
47: chaucer tale troilus tales canterbury prolog man see medieval criseyde
73: verb examples use other noun used clause two present construction
123: english translation french work original translated edition translations version published
Skewed Right
These topics rose to prominence more recently, after World War II or even more recently.
20: reading text reader read readers texts textual woolf essay Virginia
10: own power text form subject order discourse becomes authority figure
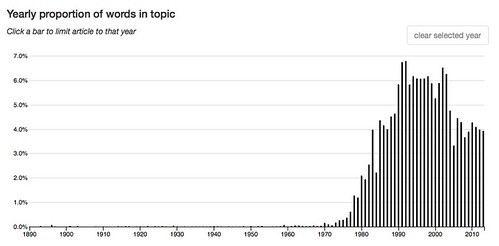
58: social work form own ideology society material production critique forms
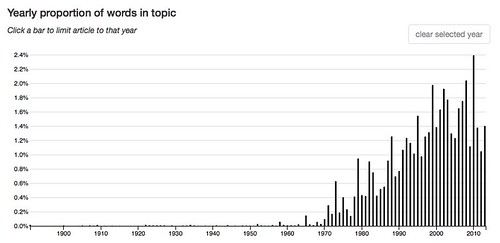
143: new cultural culture theory critical studies contemporary intellectual political essay
I looked up what the big four topics got labeled using my "correlation" strategy -- take the top 50 words in a topic and sort them by their correlation with the aggregate topic frequency.
ReplyDelete14: Instead of "other like even great" I got "great far found made" (older)
52 Instead of "other like even much" I got "way kind something like" (recent)
59 Instead of "other two first same" I got "found probably date following" (older)
114 Instead of "first even rather way" I got "view sense problem even" (recent)
I think that makes them just a shade more understandable historically, although big sprawling topics remain hard to interpret. Another thing one can do, of course, is just use a more aggressive stopword strategy in forming the original model.
On stopword strategy, you might take every word that’s in two or more megatopic, put it on the stoplist; and then rerun the analysis. The expectation being that those topics would break apart into smaller more interpretable topics or even that their tokens would be ‘absorbed’ into other topics. Is that the idea?
DeleteI’ve been wondering if we might be looking at different overall organizational strategies, say narrative or comparison and contrast in an argument. You can tell narratives about quite different bodies of texts, but you need the same kind of connective tissue for those otherwise different narratives. That connective tissue might then show up as a large topic.
I note that, in this case, what got my attention is not so much the difficulty of interpreting these topics as coherent topics in the common sense meaning of the term. If the topics had been just as sprawling, but their top ten words were quite different, I wouldn’t be so puzzled. What puzzles me is the combination of 1) different distribution over time, and 2) high level similarity among the top 10 words in each topic. If two or three distinctly different, but each uninterpretable, topics had shown up I doubt that I’d have given them much attention regardless of the temporal behavior.
So, what’s keeping these topics from merging into one supermegatopic?
Something a bit different, these topics skew new or old during the decade of the 1950s. What would happen if you broke the corpus in two at, say, 1955?
Interesting about the 1950s as watershed moment.
DeleteIt's often true that large topics have words at the top of the list in common -- driven partly by the labeling strategy that chooses most-common-words to label the topic. Doesn't necessarily mean they're similar when you dig down more deeply. And I think you're probably right that there's some kind of historically-specific "connective tissue" being revealed here.
If you take a look at this little chronology I put together several years ago you’ll see that I like to use 1957 as a reference point. That’s when Frye published his Anatomy and when Chomsky published Syntactic Structures. The year before the term “artificial intelligence” was coined and the year after Lévi-Strauss published Structural Anthropology.
Delete1957 is also when the Russian’s launched Sputnik, and that got the federal government to begin pouring money into higher education. Some of that money found its way to humanities (something the J. Hillis Miller mentions in one of his interviews). So, a portion of the cohort that would lay the intellectual groundwork for what became Theory, those folks went to graduate school on federal money kicked free by Cold War anxiety.
And a bit of that shows up in your topic 149, which looks like foreign language education. I’ve got a post on that topic. The articles that come to the top are all from that period and are about foreign language ed. What’s particularly interesting about that topic is that it has three distinct peaks. One at the beginning that falls off by about 1910, this middle peak during the 1950s and 1960s, and then a somewhat smaller rise before and after 2000.