I’ve said a bit about virtual reading here on the New Savanna. By that I mean that the ‘reading’ is being done by a computer system that is tracing the path of a text through a semantic space of high dimensionality. I’ve recently come across a very interesting paper that opens up the possibility of a different kind of virtual reading. In this case a real reader is doing the reading. But they’re doing it while in listening to a text read to them while they’re in an fMRI machine. That means that we can follow this real reading as it activates a reader’s brain. But, and here we go virtual, we can follow that reading as it traces a path through a neuro-semantic space of high dimensionality, 100s of millions if not a billion dimensions.
First I take a quick look at the paper that gave me the idea, then I review Andrew Piper’s work on Augustine’s Confessions. I conclude the suggesting what we could do by applying that technology to the Confessions.
Mapping the semantic space of the brain
Here’s the paper:
Huth, Alexander G.; de Heer, Wendy A.; Griffiths, Thomas L.; Theunissen, Frédéric E.; Gallant, Jack L. (2016). Natural speech reveals the semantic maps that tile human cerebral cortex. Nature, 532(7600), 453–458. doi:10.1038/nature17637
As I’ve already indicated, the basic idea is that they had people listen to stories while inside an fMRI scanner, which is sensitive to blood flow. This gives them a picture of brain activation during reading. The more active an individual voxel (3D sample of brain tissue), the more blood flows in it. Some voxels will be more active than others at any given moment, and the activity of any given voxel will vary from moment to moment. What we’re getting from the scanner is a 3D movie of blood flow in the brain.
Then they ‘translated’ that blood flow information into semantic information. How did they do that? It’s complicated, too complicated to go into here, and besides, that would just delay the time it takes to arrive at the good stuff. The investigators are able to do this because they know what stories each subject listened to, and they know where each subject was in the story at any given time-slice of the scan. They used standard NLP tools to process the texts and arrived at set of roughly 1000 words they traced through the scan. From that they calculated each voxel’s sensitivity to each word.
Consider the following image:

At the lower left you see a key that identifies broad areas of meaning. Those colors are used to color the image we see of the brain, center. The axes are centered on an individual voxel. The word cloud to the right indicates the words to which that voxel is most sensitive.
The following image presents the same information, but this time the cortical surface has been flattened.

You can play around with the neuro-semantic atlas here: gallantlab.org/huth2016/
Andrew Piper’s work on Augustine’s Confessions
Note: I’m just swiping this from an old post.
Andrew Piper, Novel Devotions: Conversional Reading, Computational Modeling, and the Modern Novel, New Literary History, Volume 46, Number 1, Winter 2015, pp. 63-98. DOI: https://doi.org/10.1353/nlh.2015.0008
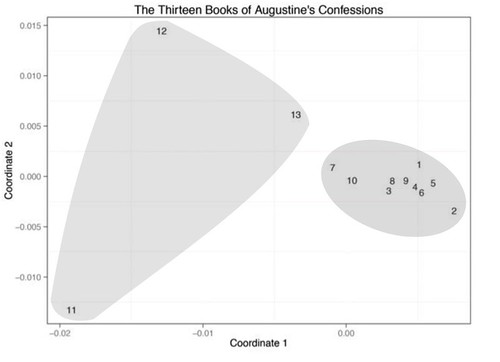
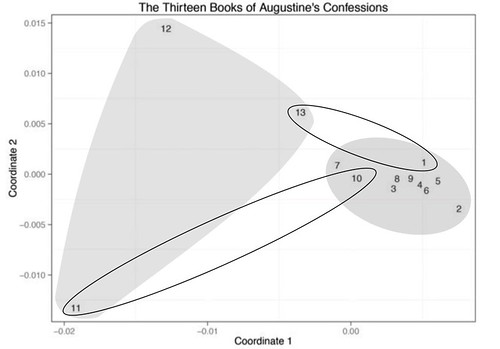
Let’s not worry about that, as we’re going to see how we can construct a much more detailed path in the next section.
Confessions in the brain
We start with the same kind of experimental set-up Huth et al. used: Subjects listening to text while in an fMRI scanner. Instead of listening to short stories, they’ll listen to individual chapters of Augustine’s Confessions. Huth at al. used two-hour scanning sessions. For the sake of argument let’s say a person can listen to one book of the Confessions in that time. That’s thirteen sessions per subject for a total of 26 hours – a lot of time in the scanner. However many subjects we use, we get a battleship’s worth of scanning data for each one.
Huth at al. only looked at the cortex, but we want to look at the whole brain. Sure, we’re interested in the semantics, but we want to see what emotion and motivation centers are up to as well. Over at Quora, Paul King, UC Berkeley Redwood Center for Theoretical Neuroscience, informs us that a high-resolution scanner (1 cubic millimeter per voxel) will cover the brain in about a million pixels. We’re measuring each voxel’s sensitivity to each of 1000 words.
There are two very different ways of looking at this data. If you want to see how the brain is responding to the text moment by moment, then you are going to want to examine the 3D volume of the whole brain. You could move through the brain slice by slice, which can be oriented however is convenient, or you might want to examine specific structures while ignoring the rest of the brain. There are many ways to skin this particular conceptual cat.
But I’m interested in how the brain traces a path through this space. That’s a different kettle of conceptual fish. What I want to do is to construct a space where each point in that space corresponds to the state of the whole brain at a moment in time. For that we’re going to need a space of a how many dimensions? We’ve got a million voxels and 1000 pieces of information for each one. That means we’re going to need a space of 1 billion dimensions. That’s pretty high for computational criticism, but a drop in the bucket for state-of-the-art machine learning (where models have 100s of billions of parameters).
Obviously, we cannot visualize a path through a space of a billion dimensions. We’re going to have to project that path into two or three dimensions. That’s doable, no? Not on the 3-year-old laptop the department got for you at Kwik-E-Mart, but, if you’re doing this kind of research, you’ll have access to computers that can do the job.
But what, you ask, of humanity? What does a humanist bring to this table? Close reading. Formal analysis and description. We can read the text to see what it’s doing at each point along the path through a space of a billion dimensions. And we can shed the same wisdom on those neuroscientists trying to make sense of those 3D slices.
I could go on and on, but this is enough. Is this kind of research going to happen anytime soon? I don’t really know, but I doubt it. It’s very expensive and will require a lot of cooperation across departments and schools.
One can dream.
* * * * *
It should go without saying that we can undertake this kind of investigation with any text we choose. I have a particular interest in “Kubla Khan” and Heart of Darkness because I’ve done quite a bit of work on them. I’d also like to see Much Ado About Nothing, Othello, and The Winter’s Tale, for the same reason. We could also do it with movies, where we’d be interested in more than just the words spoken. Why not music, where we have no words at all? But we can still trace paths of activation in the brain.
For a discussion of which this kind of research would be of value to psychologists, indeed, why I think it will be essential for them, see my working paper, The Brain, the Teleome, and the Movies, Nov. 5, 2018.
No comments:
Post a Comment