I started exploring Jockers’ 500 themes in earnest after I’d spotted this graph, which depicts the occurrence of the DOGS topic by gender over time:
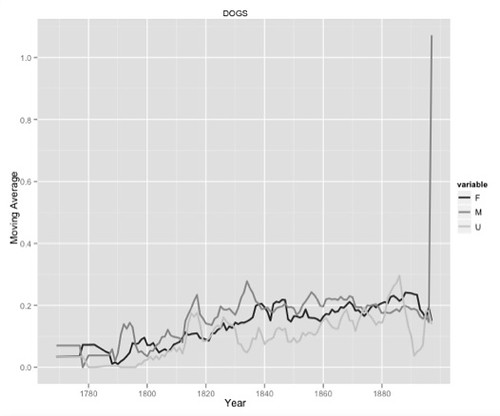
I saw that spike at the end, for male authors, and thought Call of the Wild. But alas, that can’t be, as the book isn’t in the database.
In any event, I’ve just now been looking through some more of theme plots and found with this one, for BIRDS by gender over year:
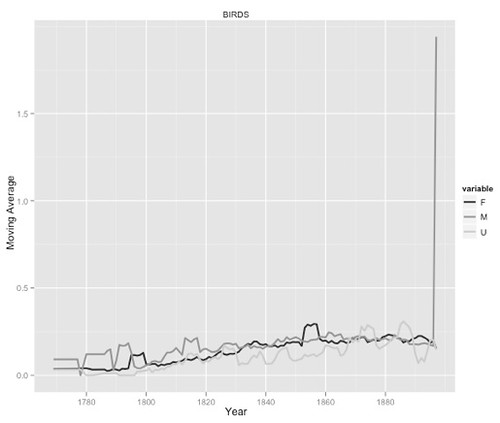
Bingo! And I wasn’t even looking for it!
The overall shape is the same as the one for DOGS, including the spike in the male line. Are we looking at the same book or books in that spike?
Here we’ve got the occurrence of these two themes by nation over time, DOGS first, then BIRDS:
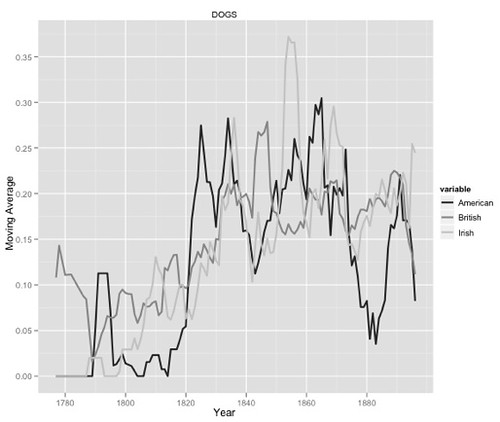
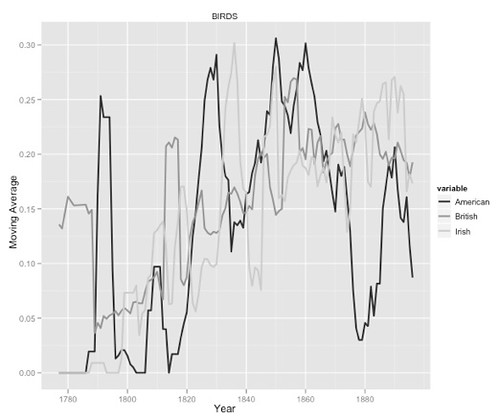
The shapes of these curves are roughly similar. In particular, look at the lines for American authors (black). Notice, for example, the spike around 1790 and the trough at 1880.
What’s going on here?
Of course I don’t know. But I’d like to.
I’ve been spending a fair amount of time trolling through these charts and graphs. My procedure is a mixture of random or at least weakly motivated poking around and deliberate searching for something that’s consistent with what I’ve already turned up–shades of Ramsay’s hermeneutics of screwing around. Thus my original interest in the DOGS topic was weakly motivated, but once I spotted it I was strongly motivated in further searches.
Similarly, my interest in BIRDS was weakly motivated. I was just noodling. But when I spotted that spike, I became interested. I decided to look at the distributions of both DOGS and BIRDS by nation over time. And what did I find? I found that they were similar.
And that’s as far as that went. Since I don’t have access to the database I can’t poke around in it and see what books I’ve turned up. But that’s OK. The last thing I need at this time is more ability to play around and get lost in the freakin’ data.
I’d rather make a methodological point and then offer a speculation. The methodological point is simple: You’ve got to mess around with the data if you’re going to find anything interesting. Statisticians call this exploratory data analysis.
Except that I’m doing it at one remove. Jockers did a lot of messing around in order to figure out how to get a reasonable set of topics. I’m just working with what he’s produced. As I don’t have access to the system, I’m stuck with it, for better or worse.
But, what’s he given us? Five visualizations for each of 500 topics: 2500 images. That’s a lot to plough through. I happen to know a little about 19th Century British and American literature, a little about related 19th Century history–and believe me, it’s just that, a little. But what little I know, I deploy with a fair amount of intellectual sophistication.
What I’ve ultimately got on my mind is cultural evolution. And it’s my sense of how that might go that’s driving my hermeneutic screwing around. These topics wax and wane. I’ve seen some that start high and then drop. I’ve seen others that do just the opposite. Some rise in the middle. And so forth. What I’d like to do is to be able to examine the waxing and waning of topics in conjunction with the waxing and waning of genres the Moretti reported a decade ago.
Books, after all, are bundles of topics. If genre differences are more than arbitrary marketing categories–and they are–then we’d expect each genre to have a characteristic mix of topics. So there ought to be a coherent, if complex, relationship between the waxing and waning of topics and the waxing and waning of genres.
I’m thinking, for example, that there are going to be some topics that are very prominent in some one or a handful of genres and not in others. There are other topics that may be widely present throughout the corpus, but never really dominant in any given genre. The MORNING topic, which is one of the most prominent in the corpus (p. 132) is likely to be one of these. Just about any story you tell will have opportunities to talk about mornings. But is there any kind of story where mornings are likely to be one of the most prevalent handful of topics?
I don’t know quite what it would take to carry out this investigation. Alas, the full corpus is not coded for genre (p. 158). So that would have to be done. Once that’s done I’m sure there are computational methods that can be used. But I’m also pretty sure that part of the process is going to involve someone sitting at huge monitor looking at and comparing various charts and graphs.
I haven’t got the foggiest idea how much time and effort will be involved nor what the result will be. But, after all, this is not the ultimate corpus of 19th Century Anglo-American novels. It may well be too small by an order of magnitude.
This feels like it’s a job for a generation of scholars. And I wouldn’t be surprised if there was a bit of crowdsourcing involved as well–how else are we going to get all those texts actually read by someone? For in the end, that’s going to have to be done. We may never want to undertake a detailed analysis of every text, but sooner or later we’re going want to more about each text than we can garner from a thematic catalogue.
Finally, let me point out that this is all about PATTERNS. Yes, there’s a lot of number crunching involved. But what’s really important are the patterns displayed in those graphs. Those patterns may be built over numbers, but they cannot be reduced to them. You have to visualize them to see what’s going on. That's what exploratory data analysis is all about, eyeballing plots to find patterns.
* * * * *
Previously:
- Reading Macroanalysis 1: Framing: Hyperobjects, Objectification, and Evolution
- Reading Macroanalysis 2: Metadata and the Emperor’s New Clothes
- Reading Macroanalysis 2.1: How do we make inferences from patterns in collections of books to patterns in populations of readers?
- Reading Macroanalysis 3.0: Style, or the Author Comes Back from the Dead
- Reading Macroanalysis 3.1: Style, or Measuring the Autonomous Aesthetic Realm
- Reading Macroanalysis 4: On the matter of “the”
- Reading Macroanalysis 5: An Interlude on Scale: Micro, Meso, and Macro
- Reading Macroanalysis 6.1: Theme–Dogs, Gold, Slavery, and Awakening
- Reading Macroanalysis 6.2: Theme, Moby Dick in the Context of Literary Culture
- Reading Macroanalysis 7: Influence, or the evolving dynamic integrity of the aesthetic sphere
- Reading Macroanalysis 7.1: Visualizing the Geist of 19th Century Anglo-American Literary Culture
No comments:
Post a Comment